[Operating System] 파일 및 파일 시스템
우리는 컴퓨터를 이용하면서 파일을 아주 자연스럽게 사용하고 있습니다. 이러한 파일들의 관리 역시 OS 를 통해 이루어집니다. 이에 대해 자세히 알아보도록 합시다.
파일이란 무엇이고, 운영체제는 파일을 어떻게 관리하는가?

파일이란? : 보조 기억장치에 저장되어 전원이 꺼지더라도 지워지지 않는 정보의 저장단위.
이 파일을 이용하여 우리는 정보를 읽고 쓸 수 있으며, 다른 프로그램의 입력/출력을 위해서도 사용할 수 있습니다.
파일의 종류로는 다음과 같은 것들이 있습니다.
- Regular File : 일반적인 파일
- Directory : 우리가 아는 폴더에 해당합니다.
- Device File : 장치 파일, 외부 연결 기기를 추상화 한 파일입니다.
- Link : 우리가 아는 바로가기에 해당합니다.
- Socket, Pipe : 프로세스간 통신을 위해 사용되는 파일입니다.
OS는 File Management 를 수행한다고 하였습니다. 이 때, File Management 의 대상은 파일 그 자체와, 파일 시스템이 됩니다. 파일 시스템이란, 파일을 관리하는 체계를 의미하며 어디선가 들어본 "NTFS, EXT4" 등이 파일 시스템에 해당합니다.
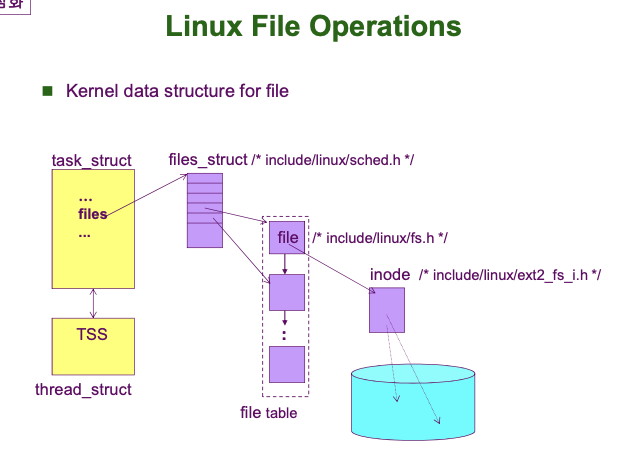
FCB
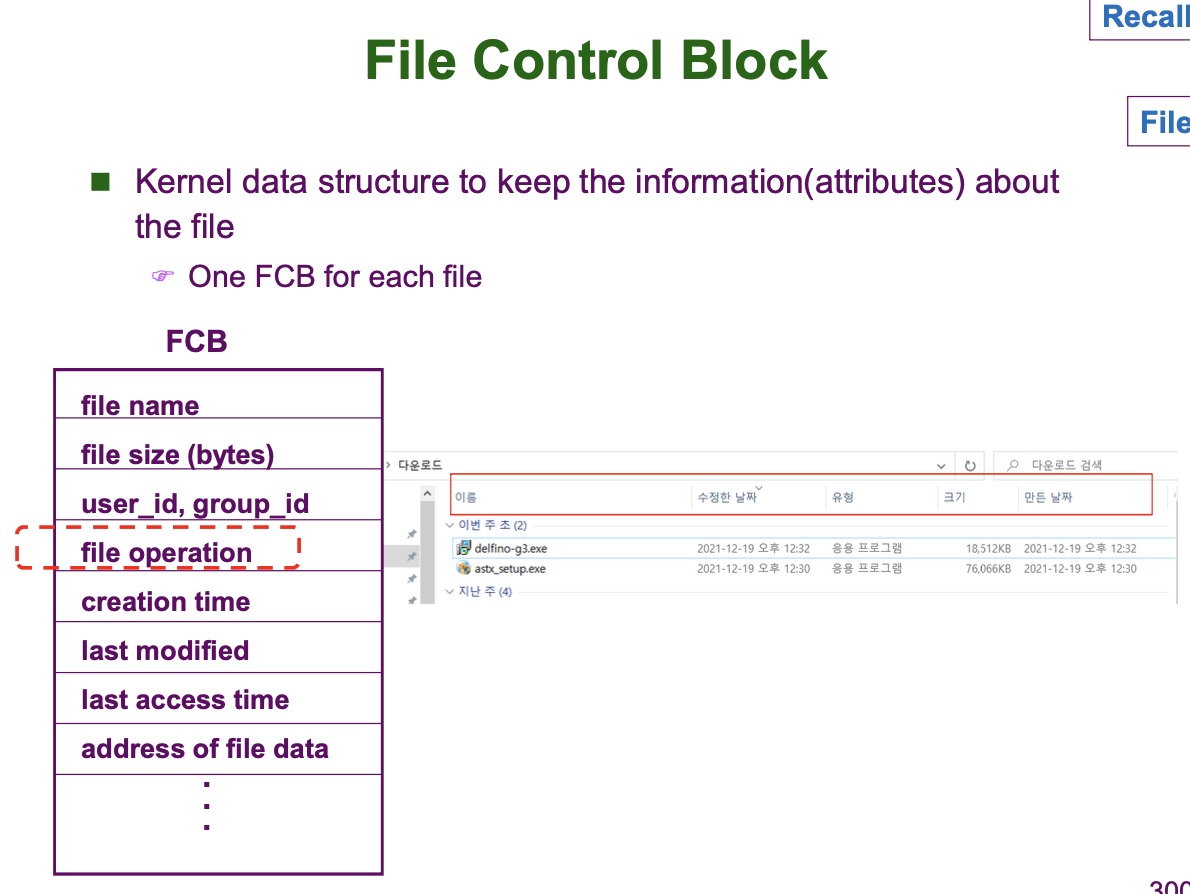
OS 는 File Management 를 위해 파일이 생성될 때 파일에 대한 정보를 저장하기 위한 별도의 Data Structure 를 운영체제 내부에 만듭니다. 이 Data Structure 가 FCB (File Control Block) 입니다.
FCB 는 파일의 이름, 파일의 크기, 생성한 사람, 디스크 내 저장된 위치, 접근권한, File Operation (이전 사진에 나온 Read, Write, Open, Create ...) 등의 파일 메타데이터 즉, 파일에 관한 정보를 저장합니다. 다시 한 번 강조하면 FCB 는 사용자가 직접 만들고 관리하는 것이 아니라 OS 가 알아서 생성/관리합니다.
우리는 파일-FCB 와 유사한 관계를 이미 다룬 적 있습니다. 바로 프로세스-PCB 입니다. 프로세스가 존재하면 그에 대한 PCB 도 반드시 존재해야 합니다. 마찬가지로, 파일이 존재하면 FCB 도 반드시 존재해야 합니다. 또, 프로세스는 메인 메모리에 존재하므로, PCB 도 메인 메모리의 Kernel Context 내에 존재했습니다. 하지만 파일의 경우, 보조 기억장치에 존재합니다. 파일이 존재할 때 FCB 도 반드시 존재해야 합니다. 따라서 FCB 는 OS 가 생성/관리하지만 저장은 보조 기억장치에 저장됩니다.
OS 의 File Management 는 무엇을 수행하는가?
OS 의 File Management 는 다음과 같은 기능 + 추가적인 기능들을 수행합니다.
1. 파일이 보조 기억 장치의 어떤 주소 (보조 기억장치에서의 위치는 데이터 블럭이라는 단위로 관리됩니다.) 에 위치하는 지 식별
2. 여러 사용자가 하나의 파일에 동시 접근할 때 동시성 문제가 발생할 수 있음. OS는 이를 관리하는 방법이 있음.
3. 어떤 파일에 대한 접근 권한을 관리함.
4. 파일의 크기가 커지면 보조 기억 장치의 free block 을 할당함.
운영체제는 파일을 어떻게 다루는가?
앞서 운영체제는 다음 두가지를 다루어 File Management 를 수행한다고 하였습니다.
- 파일
- 파일 시스템
지금부터 운영체제가 파일을 어떻게 다루는 지 살펴봅시다.
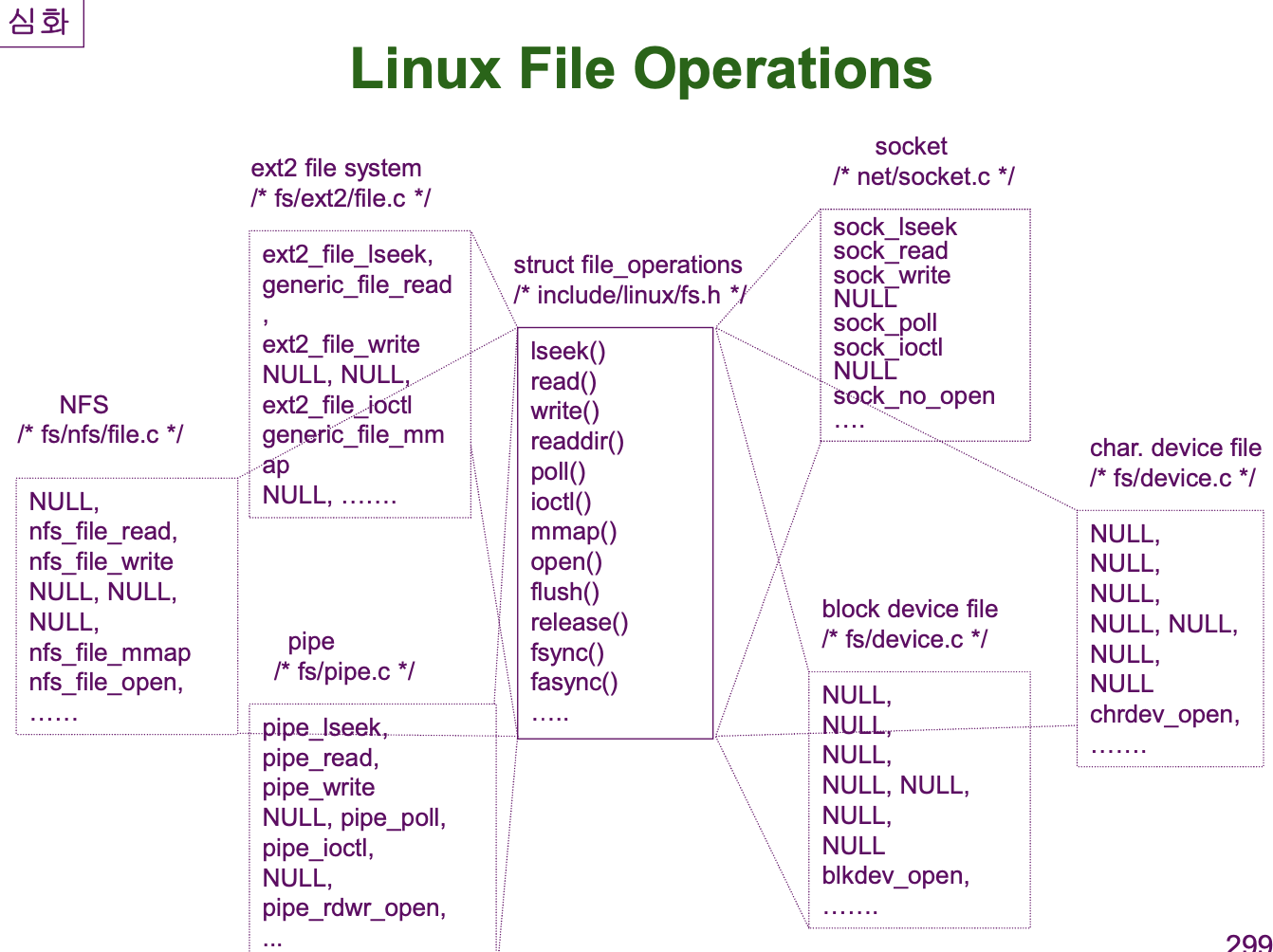
운영체제는 다음과 같은 File Operation 을 통해 File 을 다룹니다.
꽤 많은 Operations 가 있는데 이 중 몇가지에 대해서만 알아보도록 하겠습니다.
Open : File 은 보조 기억장치에 저장된다고 하였습니다. 보조 기억 장치는 상대적으로 용량이 매우 큽니다. 파일에 존재하는 정보를 읽거나, 새로운 정보를 파일에 저장하기 위해서는 이 거대한 공간에서 특정 파일을 찾아서 메인 메모리로 가져와야 합니다. 만약 메인 메모리로 가져오지 않고 Read/Write 을 수행할 때마다 보조 기억장치에서 그 파일을 찾으러 다니면 많은 시간이 소요될 것입니다.
따라서 운영체제는 Open System Call 을 통해 보조 기억장치에서 파일을 찾아 (정확히는 FCB 입니다.) 메인 메모리에 올립니다. (어떻게 찾아 오는 지는 파일 시스템에서 다룹니다.) 즉, 읽기/쓰기 등의 작업을 하기 전 원활한 File Operation 을 하기 위한 준비작업을 수행하는 것이 Open System Call 입니다.
Close : Open 과 반대되는 작업을 수행합니다. File Operation 들을 마치고 더 이상 이 파일에 대해 작업하지 않으면 메인 메모리의 공간을 확보하기 위해 Open 에서 했던 작업들의 반대 과정을 수행합니다.
Example : Device File
위에서 파일에 대해 소개할 때, 특수 파일 중 하나로 Device File 을 언급하였습니다. File 의 한 예시로 이 디바이스 파일 (혹은 장치파일) 에 대해 알아보도록 하겠습니다.

위 그림에 명시된 대로, 디바이스 파일은 특수 파일의 일종으로서 입출력을 수행하기 위한 파일입니다. 디바이스는 특수파일로 일반 파일과 달리 파일 사이즈에 대한 Attribute 정보가 없습니다. 하지만, Major_number, Minor_number 와 같은 Attribute 들이 존재합니다. mknod 를 사용할 때 [b|c] 는 이 장치가 Block(Generally, 4KB) 단위의 데이터(디스크)를 다루는지, Character 단위의 데이터를 다루는지 (키보드, 마우스)에 대한 flag 입니다. major_number 는 장치의 종류, minor_number 는 장치의 개수 (순서) 를 의미합니다.
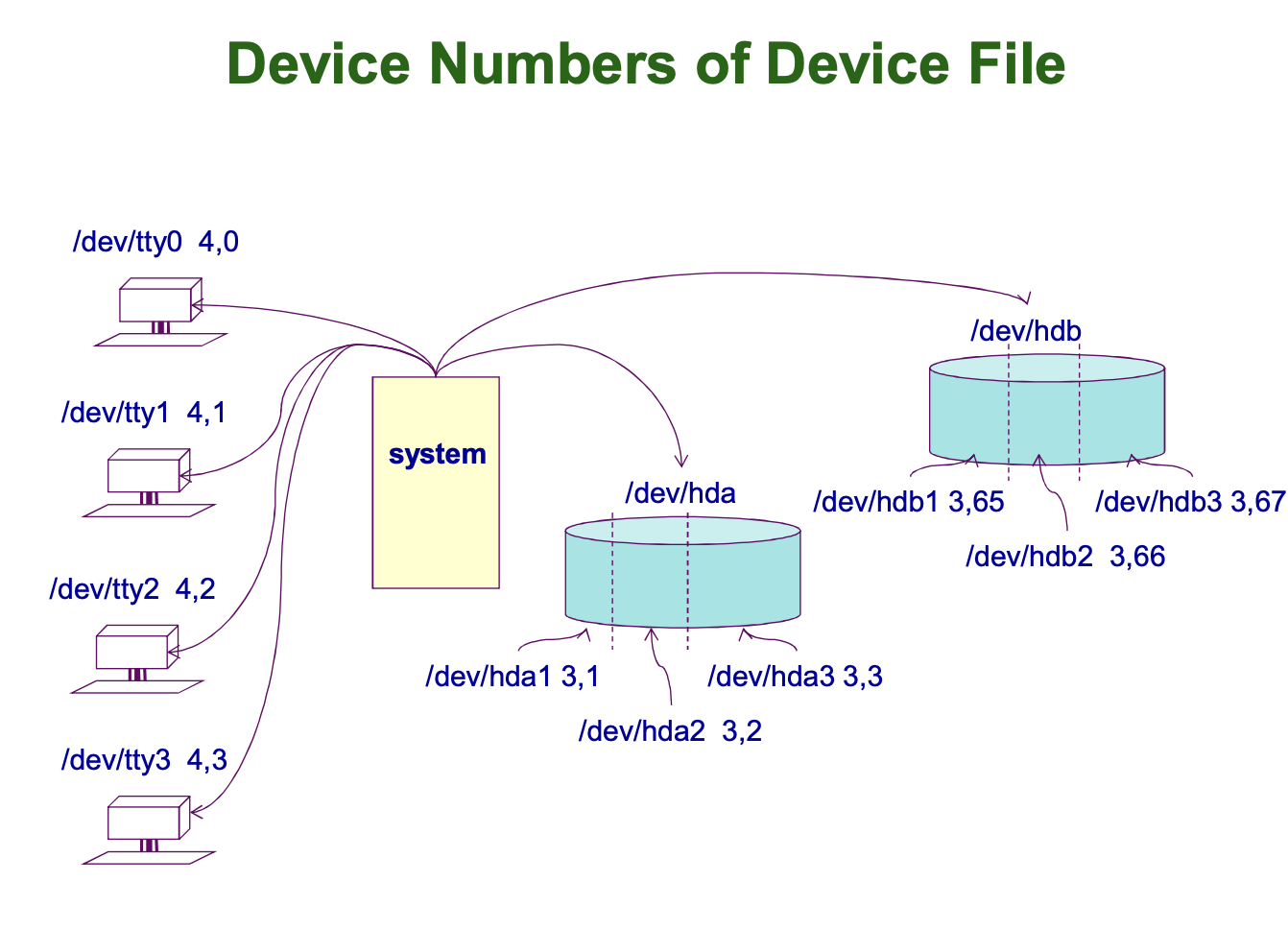
위 그림에서 hda 를 살펴보면, 하드 디스크(hda)가 System(본체)에 연결되어 있습니다. hda 는 hda1, hda2, hda3 로 파티셔닝 되어 있는 상태입니다. 이러한 상태를 아까 위의 그림과 같이 device file 로 추상화 하여 관리하고 있습니다.
TTY 는 Teletype 의 약자로, 입출력을 할 수 있는 모니터와 키보드 (Terminal) 을 의미합니다. 개인용 컴퓨터에서는 모니터와 키보드가 하나씩이라 터미널이 여러개 있다는 것이 생소할 수 있지만, 여러명이 공유해서 사용하는 서버 컴퓨터의 경우 각 사람마다 터미널이 부여되어 컴퓨터에 접근할 수 있습니다. OS 는 이러한 터미널들을 Device File 로 생성/관리합니다. 즉, 터미널을 통해 오가는 입출력이 Device file 에 정보를 입출력하는 것으로 추상화 되어 관리됩니다.
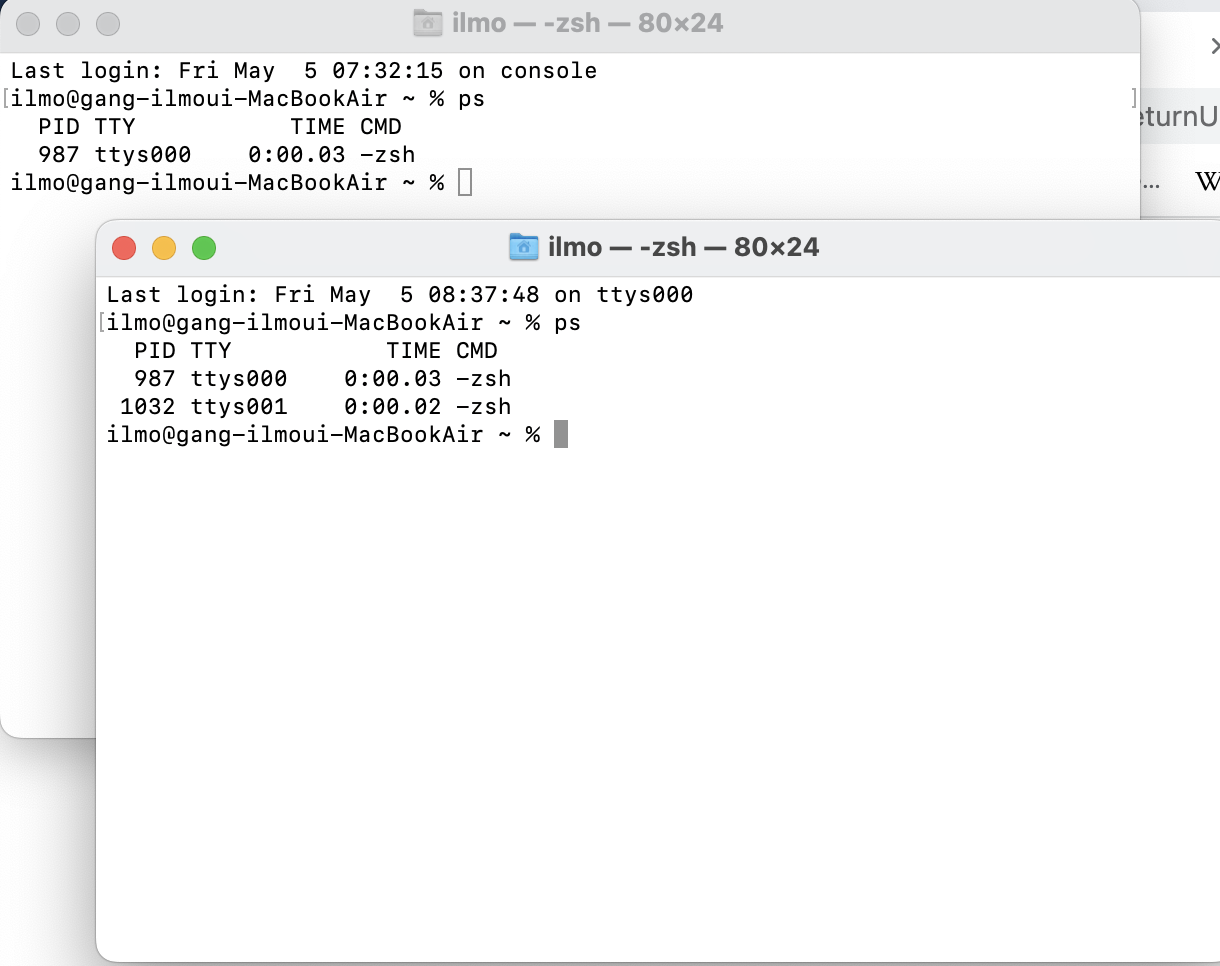
이렇게 본체에 연결된 하드웨어들을 Device File 로 추상화하여 관리하는 이유가 무엇일까요?
그 이유는, 장치의 타입이 너무 많기 때문입니다. 장치를 제조한 제조사마다 장치 (하드웨어) 의 특성이 다 다를 것입니다. 이 하드웨어의 모든 특성을 고려하여 OS 는 데이터를 주고받을 수가 없습니다. 만약 OS 가 1월에 나왔는데 새 장치가 3월에 출시되었다면 이 OS 는 OS 업데이트를 하지 않는 한 1월 이후에 출시된 장치를 사용할 수 없습니다.
이러한 문제를 해결하기 위해 장치 (하드웨어) 들을 대표하는 Device File 을 만들고 이를 통해 입출력을 수행하는 방식이 필요한 것입니다.
다음은 리눅스 장치파일의 번호들입니다. 소스코드를 찾아보니 지금에 와서는 장치파일이 더 늘어나서 그런가 260번까지 존재합니다.

Example : Directory
이번에는 파일의 특수한 형태 중 하나인 디렉토리에 대해 살펴보겠습니다.

Directory 는 앞서 설명했듯, 우리가 익숙히 알고 있는 폴더입니다. 보다 명확한 정의는 Directory 란 파일 메타데이터들을 갖고 있는 파일입니다. 이전에 파일 메타데이터들은 FCB 라는 Data Structure 로 저장되어 관리된다고 하였습니다. 디렉토리는 이러한 파일 메타데이터를 직접 갖는 것이 아니라 FCB 들을 가리키도록 구현되어 있습니다. 즉, 논리적으로는 파일 메타데이터들을 갖지만, 실제적 구현은 갖고 있는 파일에 대한 이름과, FCB 들의 식별자만 갖도록 구현되어 있는 것입니다.
디렉토리의 계층 구조가 어떻게 조직되어 있는지 살펴봅시다.

위의 설명대로 디렉토리의 계층 구조는 root(혹은 master) 디렉토리부터 시작되어 디렉토리 하위에 디렉토리 혹은 파일 (물론, 디렉토리도 파일입니다.) 들이 존재할 수 있습니다. 각각의 파일들은 unique 한 path 를 가지게 되어 같은 이름의 파일이라도 서로 다른 path 를 가지고 있다면 식별가능해집니다.
우리가 익숙히 아는 폴더의 구조를 봅시다.
이제 디렉토리 하나가 어떻게 구성되었는지 살펴봅시다.

일반적으로, 디렉토리의 내용은 cat 과 같은 명령으로는 볼 수 없습니다. 하나의 디렉토리는 위 그림과 같이 byte offset, inode number, file name 으로 구성되어 있습니다.
byte offset : 디렉토리는 한 줄에 하나의 파일의 이름과 inode number 를 기록합니다. 시작 줄로부터 얼마만큼 떨어졌는지 표시하는 것이 byte offset 입니다.
inode number : 파일에 대한 메타 데이터 즉, FCB 의 식별자 정보입니다.
운영체제가 파일을 Open 하는 방법
디렉토리의 계층구조까지 배웠으니, 운영체제가 파일을 Open 하는 방법에 대해 복습하여봅시다. 파일은 보조 기억장치 (HDD, SDD) 에 존재하는 데이터 블럭 내에 저장됩니다. 운영체제가 특정 파일을 Open 하려면 그 파일이 보조 기억장치의 어떤 블럭에 존재하는 지를 알아야합니다.
이전에 어떤 파일의 블럭 위치를 FCB 에 저장한다고 이야기한 바 있습니다. 따라서 FCB 의 위치를 알면 운영체제는 파일이 존재하는 블럭의 위치도 알 수 있습니다.
그렇다면 FCB 의 위치는 어떻게 알 수 있을까요?
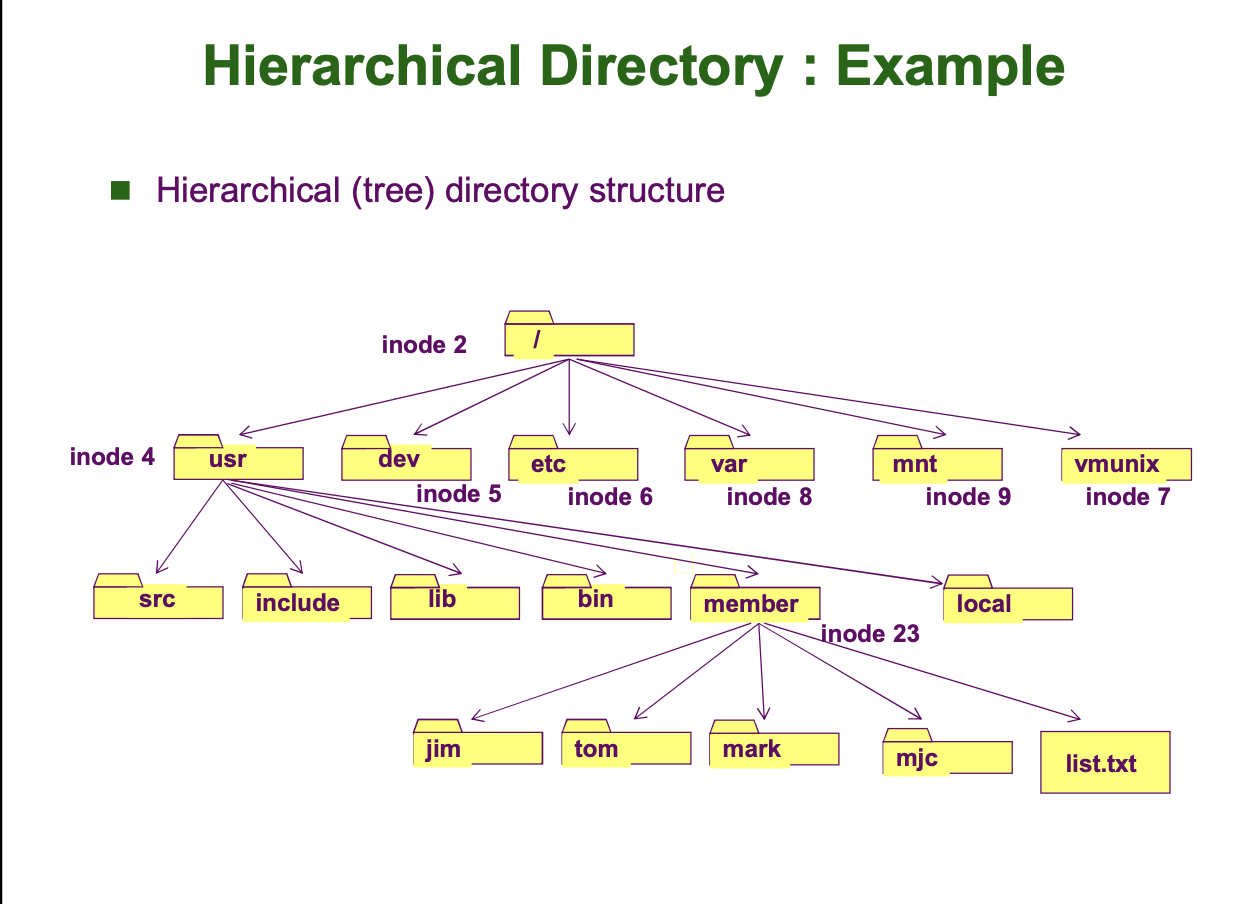
UNIX 운영체제의 경우 root 디렉토리의 FCB Identifier 즉 inode number 가 2 입니다. 따라서 운영체제는 inode number 2 를 읽어 들이고 이를 바탕으로 하위 디렉토리 혹은 파일에 접근할 수 있게 됩니다.
구체적 예시를 들어 위 계층적 디렉토리 구조에서 open("/usr/mem/list.txt", O-RDWD) 로 파일을 open 한다고 합시다. (RD,WD 는 read, write 을 의미) 그렇다면 OS 는 root 디렉토리의 FCB (inode 2) 를 읽고 root 디렉토리가 저장된 data block 의 위치를 알아내 root 디렉토리에 어떤 내용 (포함하고 있는 inode number 와 파일 이름) 을 담고 있는지 확인합니다. 그리고 root 디렉토리의 하위 디렉토리로 usr 가 존재하는지 확인하고 usr 가 존재하면 usr 의 FCB 를 읽고 usr 하위에 member 디렉토리가 있는지 확인하고 ... 의 과정을 수행하는 것입니다.
위 과정을 그림으로 표현하면 아래와 같습니다.

Dangling-Pointer Problem
위의 예시에서는 디렉토리의 구조가 정확히 Tree 의 구조를 가지고 있었지만, File 의 종류 중 우리가 아는 바로가기에 해당하는 link 라는 파일이 있던 것을 떠올려봅시다. 링크가 존재하면 디렉토리는 다음과 같이 사이클이 없는 그래프 형태를 띄게 됩니다.
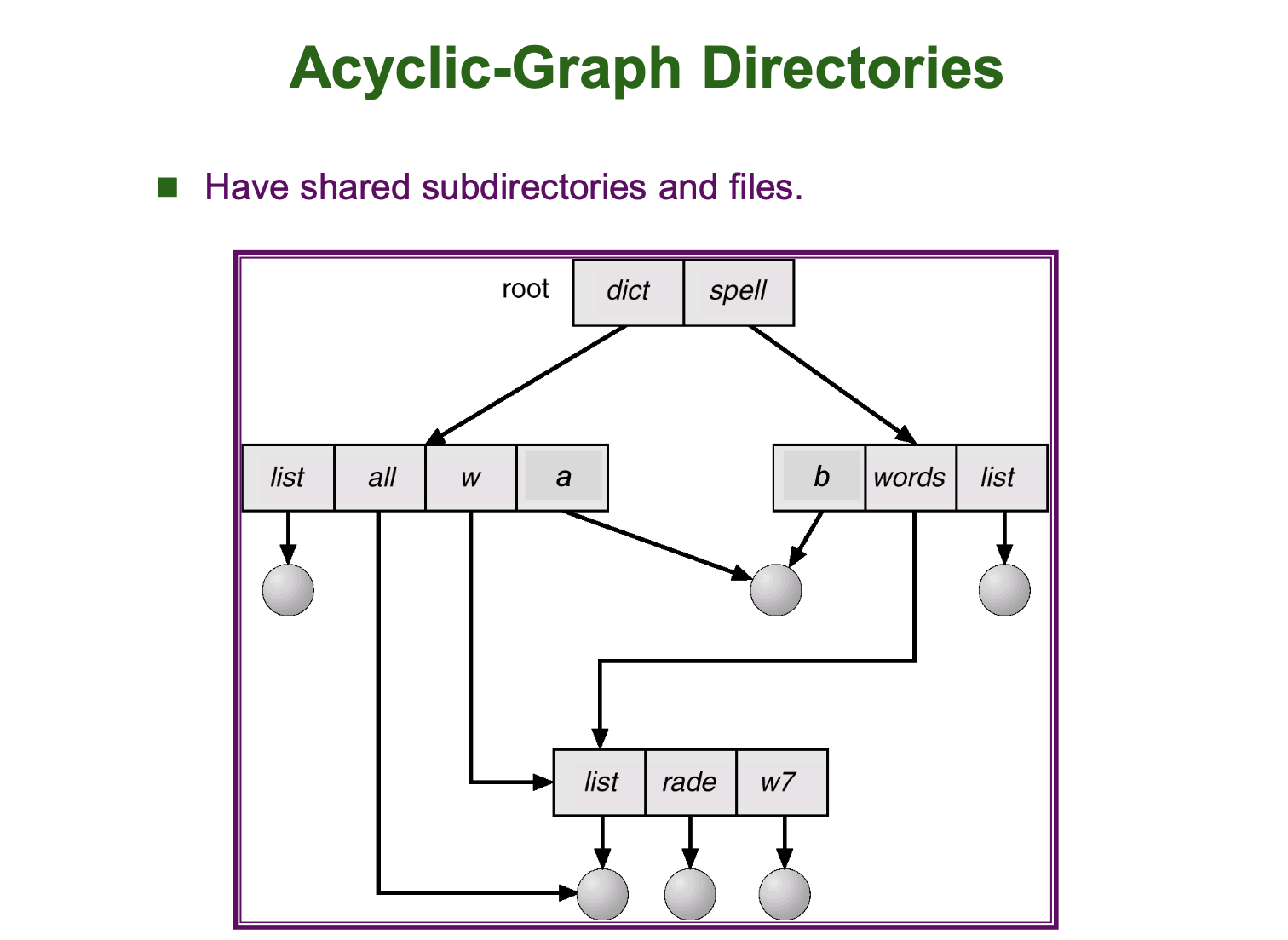
이런 그래프 형태에서는 발생할 수 있는 문제점이 있습니다. 바로 Dangling-Pointer 문제입니다. 만약 a 디렉토리 밑에 파일이 있다가 b 에서 그 파일에 대한 바로가기를 만들었다고 가정합시다.
이 때 a 디렉토리를 삭제해버리면, b 디렉토리에서 바로가기를 통해 파일에 접근하려 할 때 "파일을 찾을 수 없습니다." 와 같은 문제를 겪어 보신 적이 있으실겁니다. 이런것이 Dangling-Pointer 문제입니다.
이 문제에 대한 해법은 다음과 같습니다.
- 유저가 해결하게 그냥 둔다. (즉, 댕글링 포인터 문제를 해결하지 않는다.)
- Entry-Count 를 사용한다. a 디렉토리를 날리더라도 (count = 2 -> 1), b 디렉토리에서 파일을 가리키고 있으므로 (count > 0) 해당 파일은 삭제하지 않는다.
이 외에도 해결방법이 있지만, overhead 가 커서 사용하지 않습니다.
File 동시 사용, 접근 권한
Process 들은 IPC 를 하지 않는 한 자기 자신 외의 프로세스에 접근해서 그 Resource 를 건드릴 수 없었습니다. 하지만 파일의 경우, OS 가 적극적이로 동시 사용 문제에 관여하지 않습니다. 이 부분은 유저가 해결해야 할 문제로 두었습니다.

물론, OS 가 lock 을 제공하여 User 가 lock 을 활용해 동시 사용 문제를 제어할 수 있지만 기본적으로 OS 는 File 의 동시 사용 문제에 개입하지 않습니다.
그리고 접근권한을 설정할 수 있습니다.

파일 시스템
드디어 OS 의 File Management 의 객체가 되는 File 에 대한 내용을 마치고 File System 에 대해 다룹니다.
File System 은 디스크와 같은 보조 기억장치에 저장되는 거대한 자료구조와 이 자료구조에 접근하여 정보를 처리하는 알고리즘을 일컫는 용어입니다.
파일 시스템 자료구조는 다음과 같이 구성되어 있습니다.
- Boot Block
- Super Block (Partition Control Block)
- Directory Structure (Optional, File System 에 따라 있을 수도 없을 수도 있음)
- File Control Blocks
- Data Blocks
즉, File System 은 Block 단위로 관리됩니다.
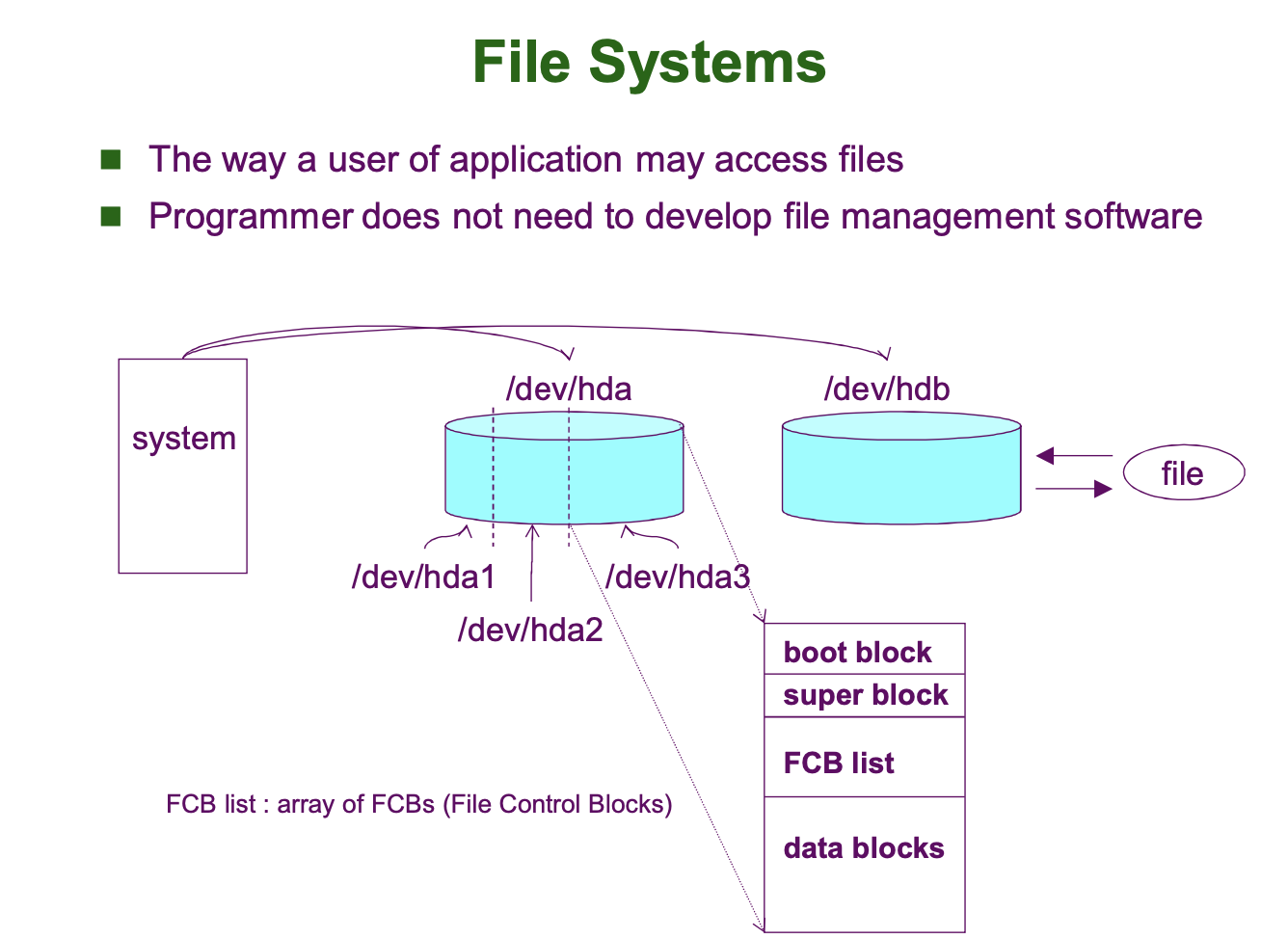
위 그림에서 알 수 있다시피, File System 은 하나의 파티션에 부여됩니다. 예를 들어, 1TB HDD 를 512GB, 512GB 로 나누어 파티션을 구성하고 각각의 파티션에 서로 다른 파일 시스템을 부여할 수 있습니다.
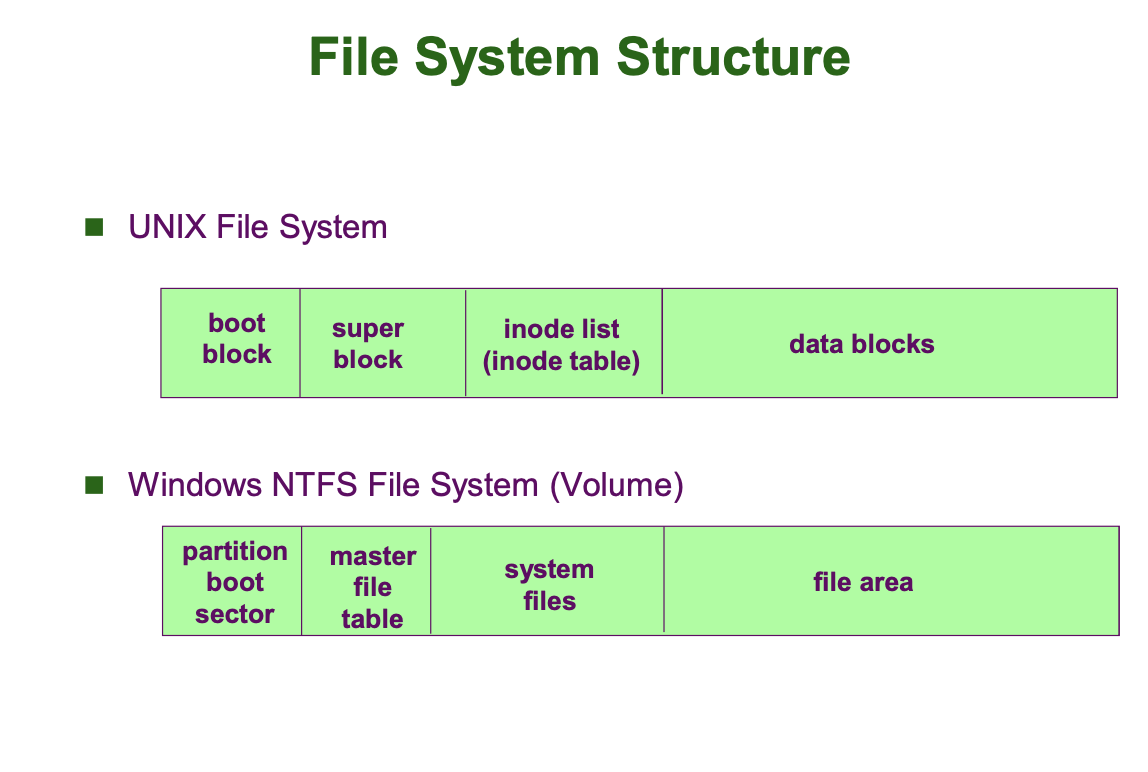
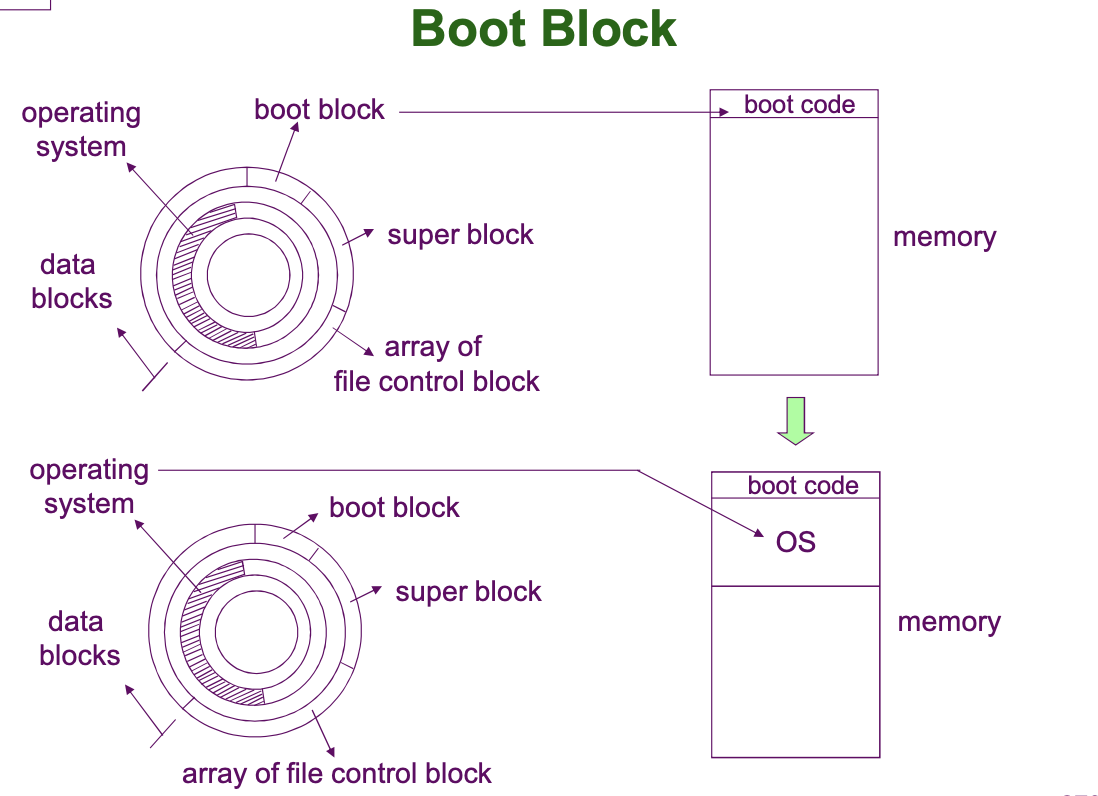
먼저 Boot Block 에 대해 자세히 알아봅시다.
이전에 컴퓨터에 전원을 공급하고 부팅이 될 때 어떤 순서로 부팅이 이루어지는 지 다뤄본 바 있습니다.
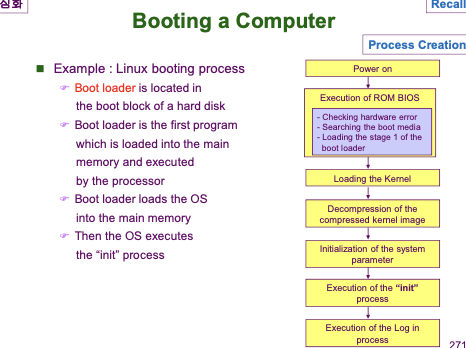
먼저, ROM BIOS 에서 하드웨어를 점검하고, 보조 기억장치의 부트로더를 메인 메모리로 불러와 OS 를 메인 메모리에 올려 부팅을 한다고 하였습니다. 이 때 이 부트로더가 저장된 공간이 Boot Block 입니다.
이번에는 Super Block (혹은 Partition Control Block) 에 대해 살펴보겠습니다.

Super Block 은 Partition Control Block 이라는 명칭에 걸맞게 해당 파티션에 부여된 File System 에 대한 정보를 저장하는 영역입니다. 이 파일 시스템에 존재하는 블럭의 개수 (Size), Free Data Block 의 개수, Free Data Block List, FCB 의 개수, Free FCB 의 개수, Free FCB List 를 가지고 있습니다.
다음으로, File Control Blocks (FCB Table) 에 대해 살펴보겠습니다.

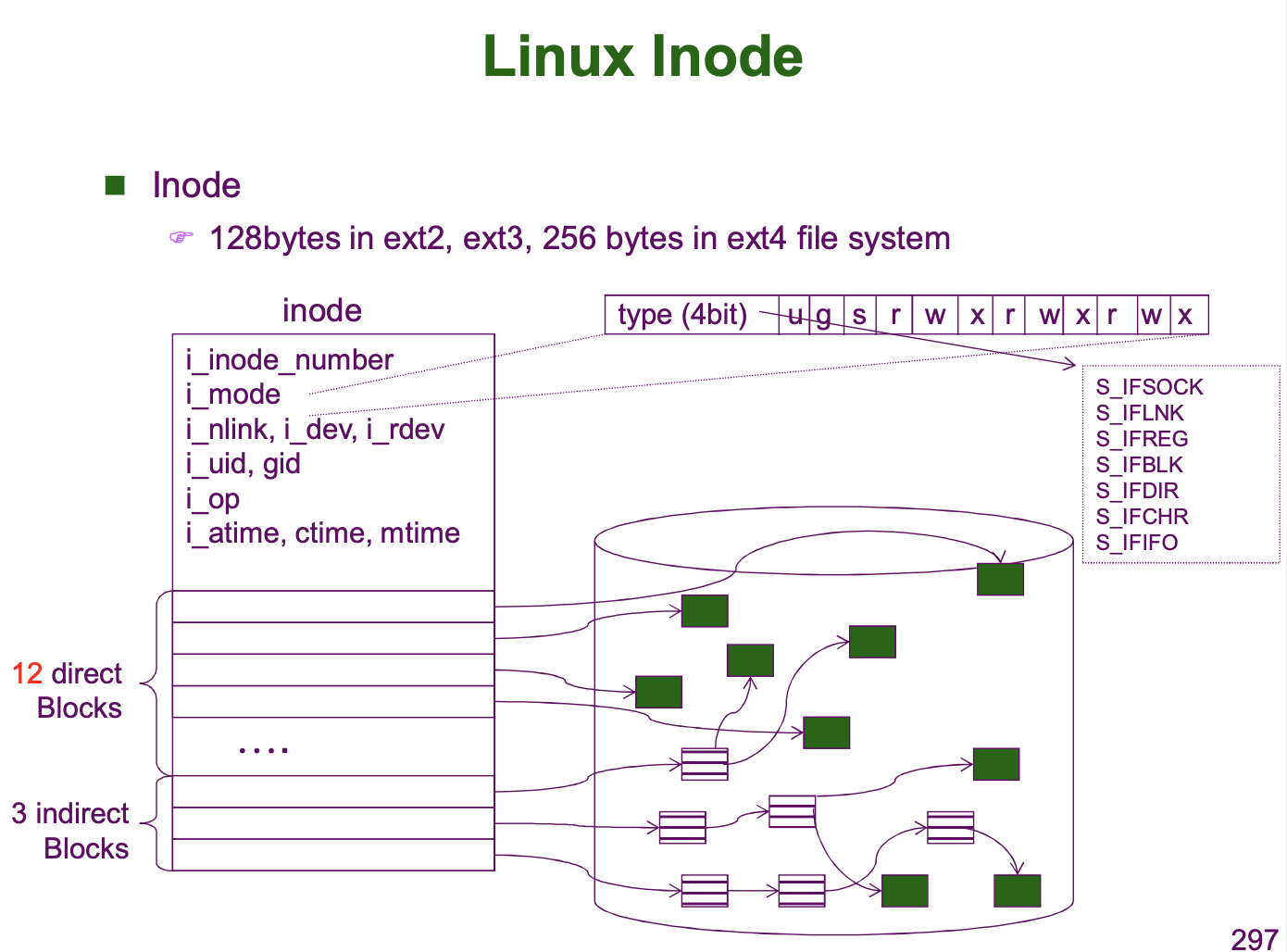
File Control Block (=FCB) 는 OS 가 만들어 보조 기억장치에 저장한다고 하였습니다. 이 FCB 가 저장되는 영역이 File Control Blocks ( = FCB Table) 입니다. Unix/Linux 에서는 FCB 를 inode 라고 지칭합니다. 운영체제는 특정 inode number 를 지정하기도 합니다. 앞서 디렉토리에 대해 살펴볼 때 root 디렉토리의 inode number 가 2 였던 것을 떠올리면 됩니다.
FCB 의 크기는 일반적으로 128bytes 라고 합니다. 현대에 와서 FCB 의 사이즈가 커져야하지는 않을까 싶어 ChatGPT 에게 물어보니 다음과 같은 결과를 얻을 수 있었습니다.

마지막으로 Data Block 에 대한 설명을 글로 마무리하겠습니다. Data Block 은 실제 데이터가 저장되는 영역입니다. 일반적으로 Data Block 하나의 크기는 4KB 입니다. 파일 데이터는 이 블록들을 할당하여 저장됩니다. 따라서 이 블록들을 할당/추적/관리할 수 있어야 합니다.
블록의 관리 (블록을 관리하는 방법)
앞서 File System 에 대해 소개할 때 File System = 블록 자료구조 + 알고리즘 이라고 말씀드렸습니다. 이번에는 이 블록들을 관리하는 방법에 대해서 알아보겠습니다.
먼저 데이터 블록을 관리하는 방법에 대해 알아봅시다.
Data Block 을 관리하는 방법은 크게 3가지가 있습니다.
- Contiguous Allocation (Not Practical)
- Chained Allocation (Poor Data Safety)
- Indexed Allocation
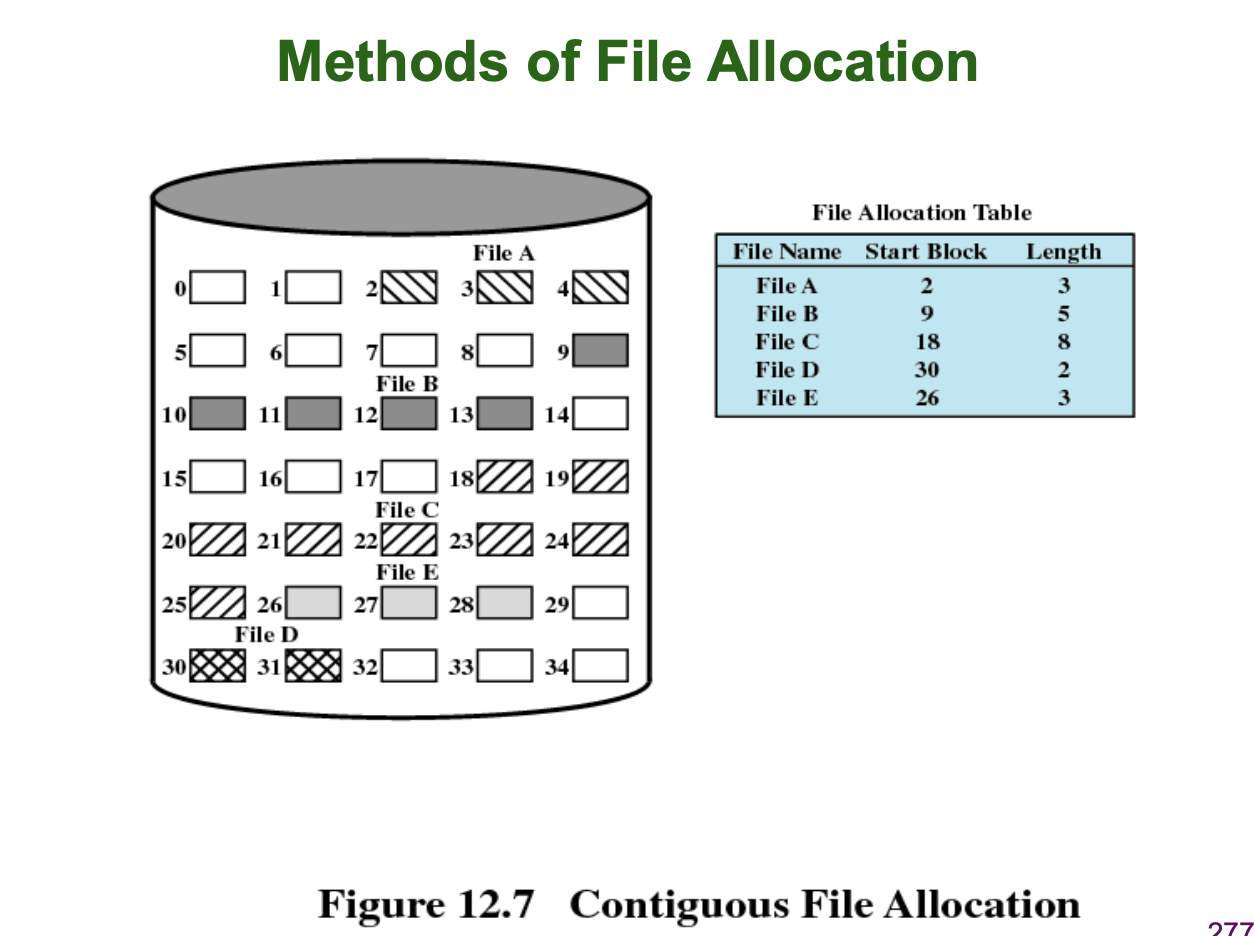
Contiguous Allocation

Contiguous Allocation 은 말 그대로 "연속적인 할당" 을 통해 이루어집니다. 보조 기억장치의 데이터 블럭을 연속적으로 할당하여 파일의 데이터를 기록합니다. 그리고 File Allocation Table 혹은 FCB 에 이 파일의 데이터 블록 시작 위치와 전체 블록 수를 기록하여 이 파일의 데이터 블럭에 접근할 수 있도록 합니다.
하지만, 외부 단편화가 생기고, File 크기가 커질 때의 관리의 어려움의 이유로 실용적이지 못합니다.
아래의 그림을 보면 Contiguous Allocation 에 대해 직관적으로 이해할 수 있습니다.
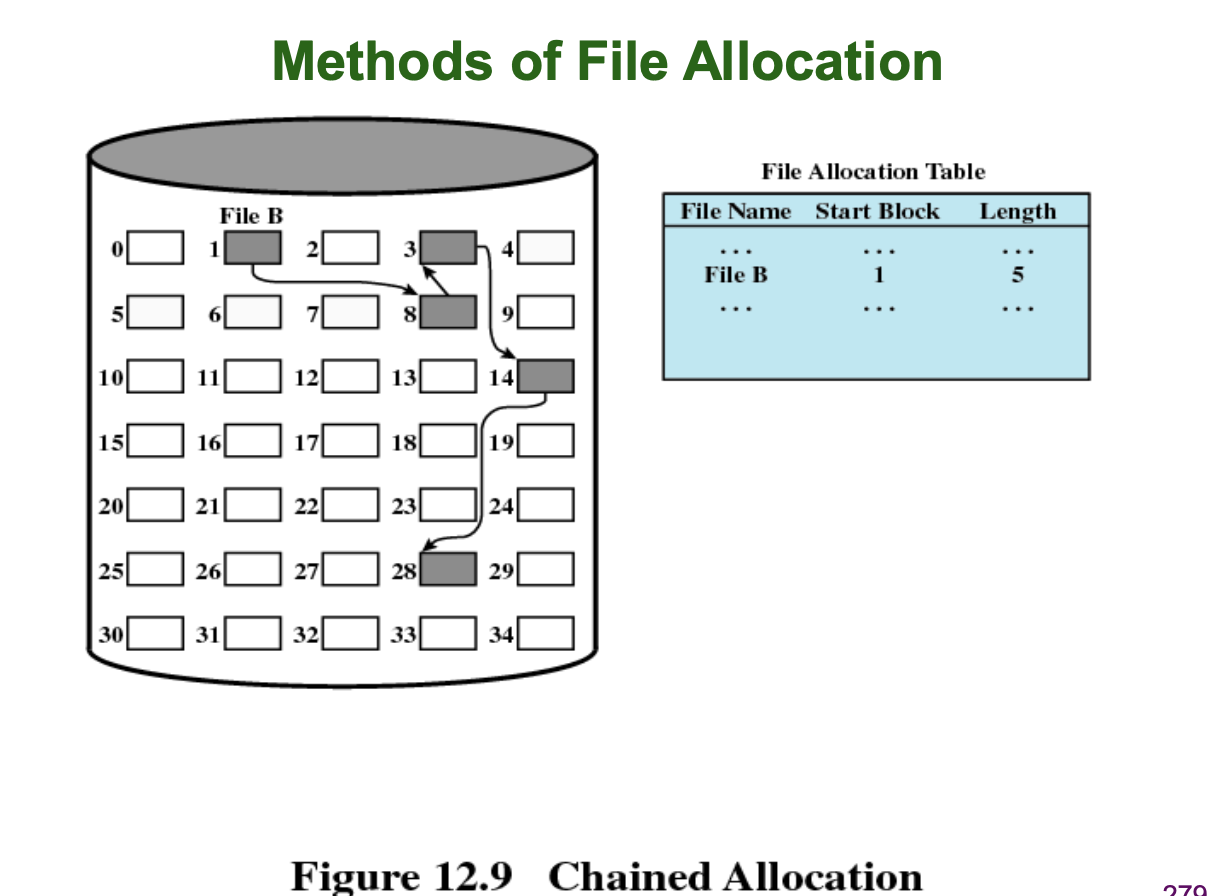
Chained Allocation

Chained Allocation 은 Linked List 형태로 데이터 블럭들을 연결하여 관리하는 방법입니다. Contiguous Allocation 과 달리 데이터의 크기를 늘이고 줄이는데 문제가 없으며, Free Data Block 을 연결만 해주면 되므로 외부 단편화 (External Fragmentation) 문제도 발생하지 않습니다. Contiguous Allocation 과 마찬가지로 File Allocation Table 에 첫번째 데이터 블럭의 위치와 총 데이터 블럭 길이를 기록합니다.
하지만, Linked List 형태이기 때문에 Direct Access 가 불가능하고 항상 첫번째 Head Data Block 부터 시작하여 데이터를 읽어나가야 하여 속도가 느리며, 연결된 Data Block 중 Bad Sector 가 발생하면 Bad Sector 이후에 등장하는 Data Block 또한 읽을 수 없는 문제점이 존재합니다. 즉 Data Safety 가 낮습니다. 또, Linked List 형태를 유지하기 위해 데이터 블록의 일부를 사용하여야 하므로 overhead 문제도 존재합니다.
Indexed Allocation

Indexed Allocation 은 데이터 블럭 중 하나를 인덱스 블럭으로 사용하여 데이터 블럭을 관리하는 방법입니다.
인덱스 블럭 내에 파일을 저장하고 있는 데이터 블럭들의 번호들을 파일의 내용 순서대로 나열하여 저장합니다. 그리고 FCB 혹은 File Allocation Table 에는 이 인덱스 블럭 (데이터 블럭) 의 식별자를 저장합니다. 이 방식은 Direct Access 가 가능하고, External Fragmentation 도 없습니다. 파일의 크기가 커지더라도 Free Block 을 추가로 할당하여 Index 블럭에 해당 Free Block 의 번호만 추가해주면 됩니다.
하지만, 여전히 Data Safety 가 좋지 않습니다. 다만, Chained Allocation 방식과 비교하면, Chained Allocation 방식은 연결된 데이터 블럭 중 하나만 날아가도 문제가 생기는 반면에, Indexed Allocation 방식은 인덱스 블럭이 날아가지 않는 한, Bad Sector 가 발생한 데이터 블럭 이외의 블럭에는 문제가 생기지 않습니다.
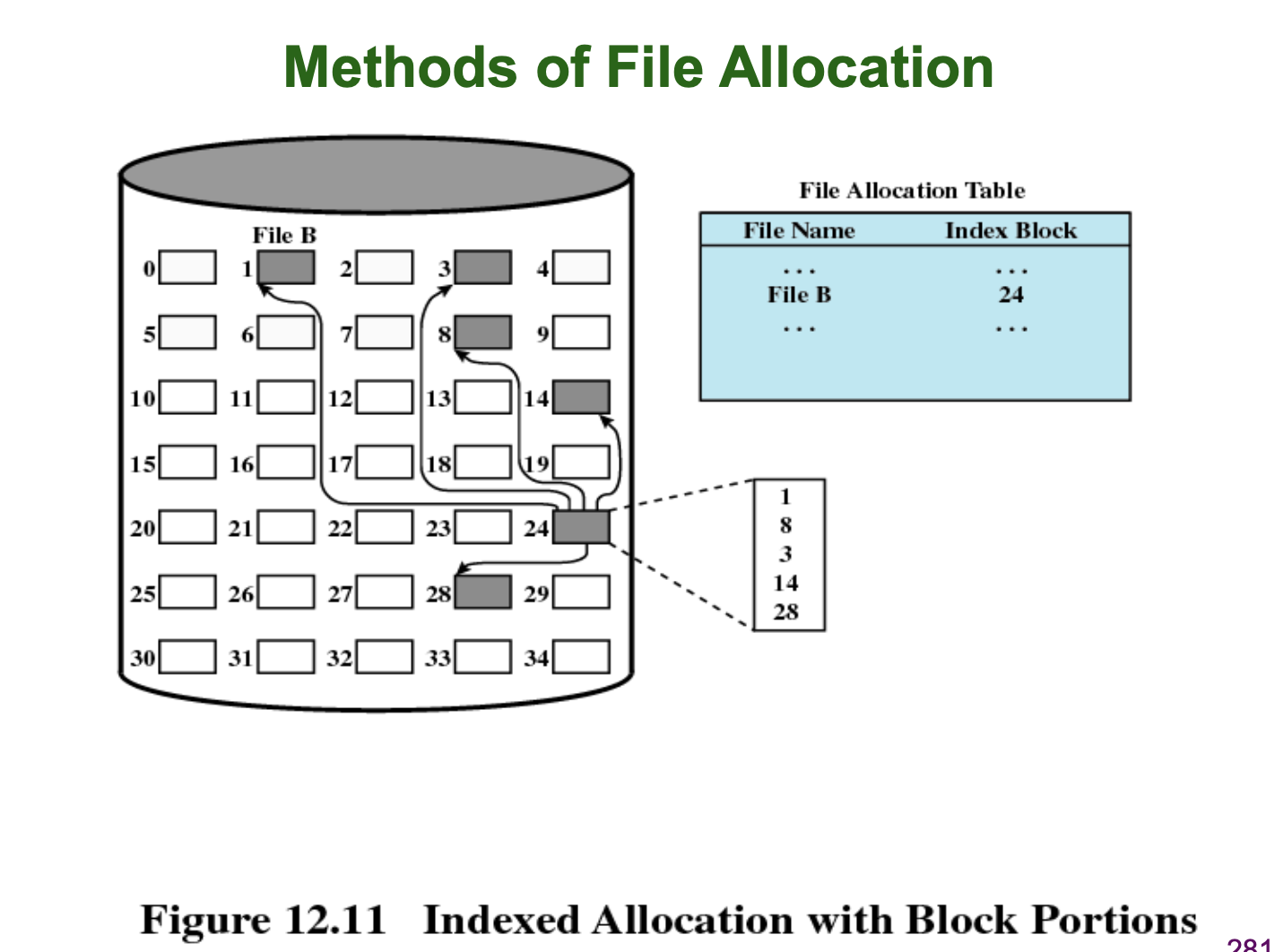
지금까지 "데이터 블럭" 의 관리 방법에 대해 살펴보았습니다.
이번엔 Free Data Block 관리 방법에 대해 알아봅시다.
Free Data Block 을 관리하는 방법은 다음과 같습니다. 그리고 기본적으로 Free Data Block 에 관한 정보는 앞서 말씀드린 것처럼, Super Block (Partition Control Block) 에서 관리됩니다.
- Counting (Simliar to Contiguous Allocation)
- Linked List (Similar to Chained Allocation)
- Grouping (Similar to Indexed Allocation)
- Bitmap
Counting

Counting 방법으로 Free Data Block 을 관리하는 방법은 Contiguous Allocation 과 유사합니다. 연속된 Free Data Block 이 존재하는 첫번째 Free Data Block 의 번호와 그 길이를 기록하여 관리합니다.
Linked List

Linked List 방법은 Chained Allocation 과 유사합니다. Free Data Block 내부에 Linked List 자료구조를 유지할 수 있는 정보를 넣어 Free Data Block 을 연결합니다.
하지만, Chained Allocation 의 문제인 중간의 하나의 블럭에서 Bad Sector 가 발생하면 뒷부분의 데이터를 읽을 수 없다는 문제는 여전히 존재합니다. 다만, Chained Allocation 과는 달리, Free Data Block 은 뒷부분의 데이터에 접근할 필요가 없으므로, 블럭을 할당하는데 많은 시간이 소요되지 않습니다.
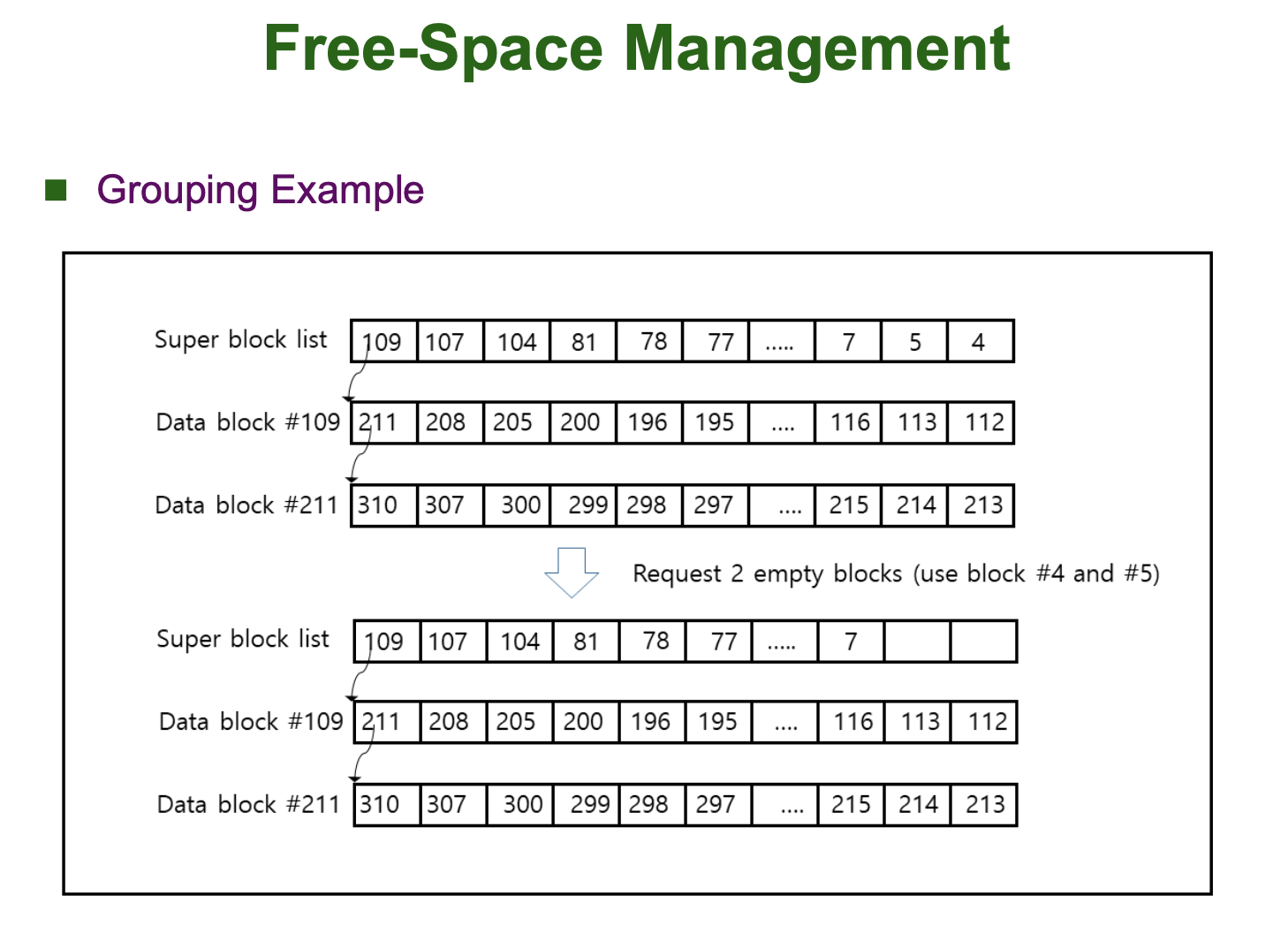
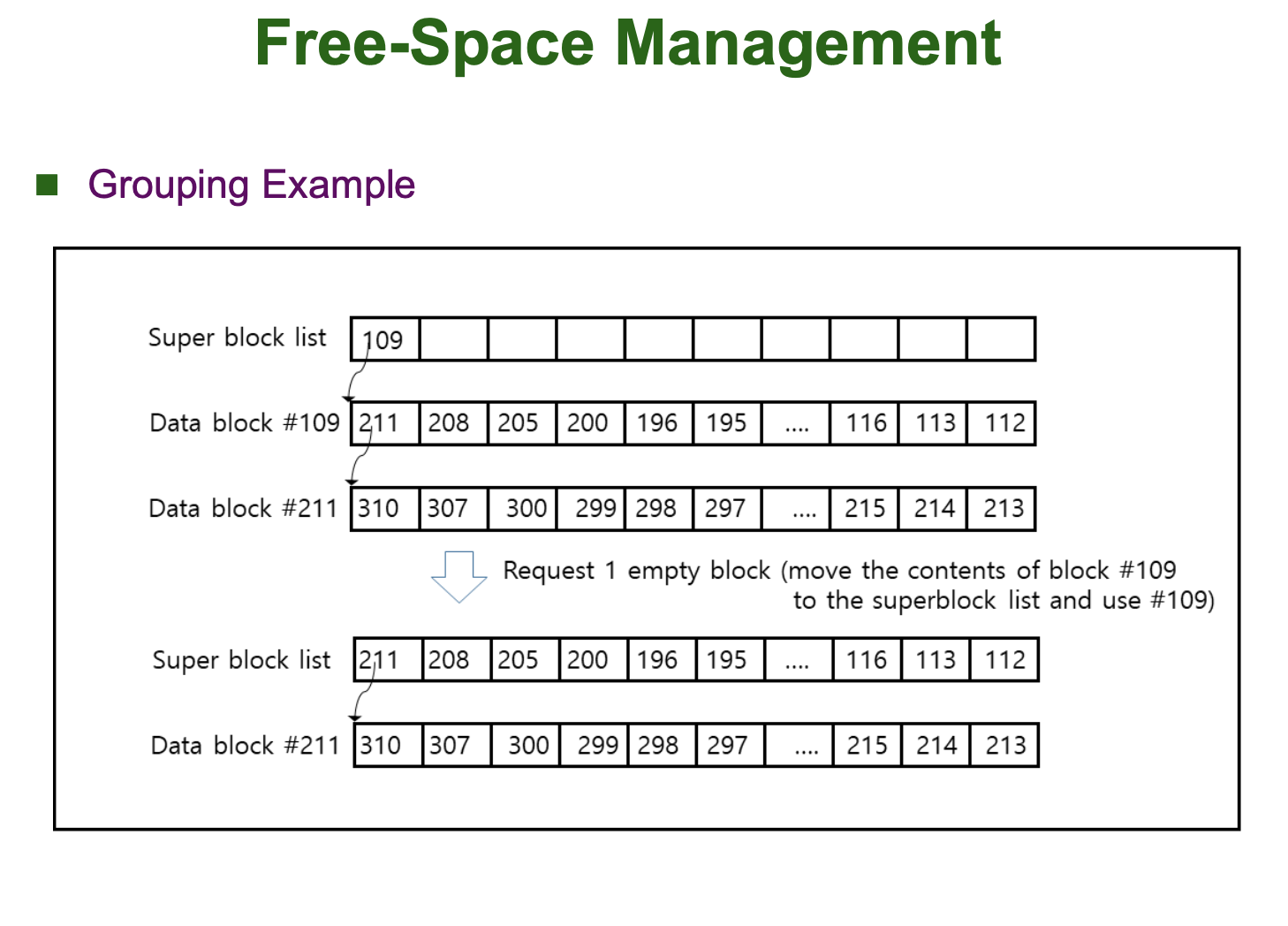
Grouping
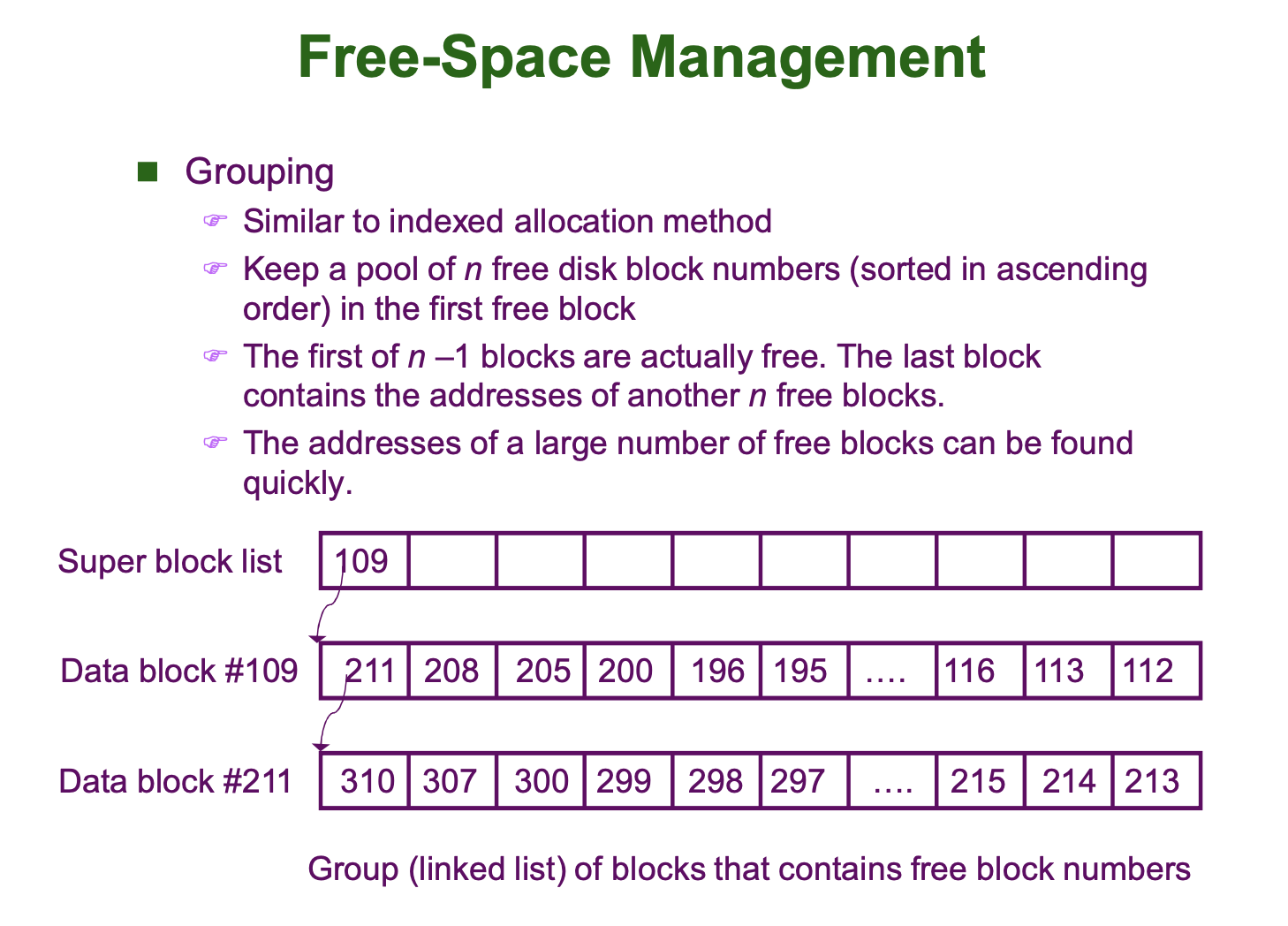
Grouping 방법은 Indexed Allocation 방법과 유사합니다.
먼저, File System 의 Super Block 에 존재하는 블럭 하나를 꺼내 Free Data Block 들의 번호들을 저장합니다. 그리고 이 Super Block 이 가득차면, Super Block 에 저장된 Free Data Block 중 하나를 골라 Linked List 처럼 연결하여 그 Free Data Block 에 또 다른 Free Data Block 의 번호들을 저장합니다.
Grouping 방법은 초기 Unix 에서 사용되었습니다.
아래 그림을 보면 Grouping 방법에 대해 직관적으로 이해할 수 있습니다
Bitmap
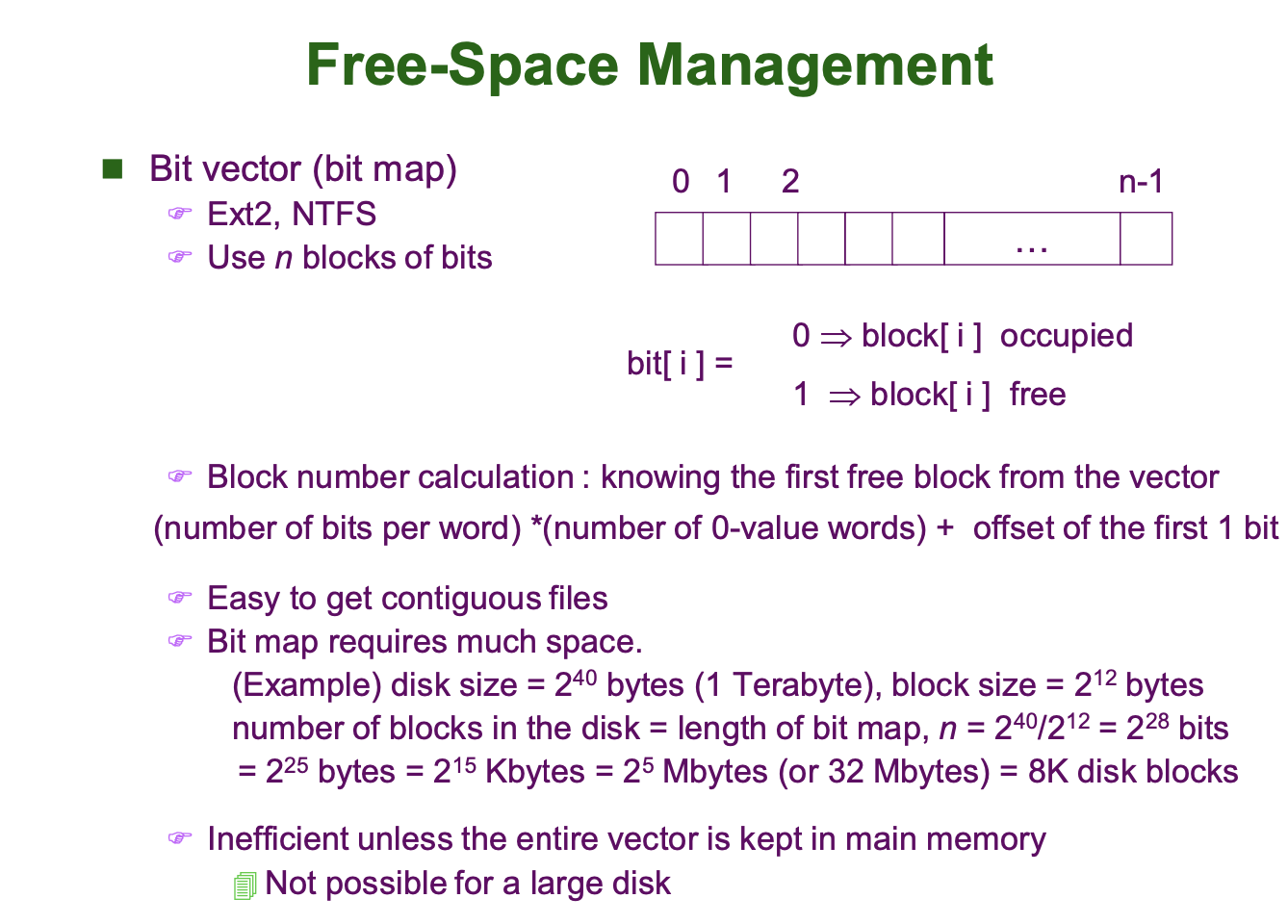
Free Data Block 을 관리하는 마지막 방법인 Bitmap 방식입니다. Bitmap 방식은 Ext2, NTFS 파일시스템에서 사용됩니다.
Bitmap 방식은 디스크에 존재하는 모든 데이터 블럭의 Occupied 상태를 Bit Vector 로 표시합니다. 따라서 블럭 수만큼의 비트가 필요합니다. 따라서 디스크의 크기가 커 비트벡터의 길이도 길어지면 디스크의 공간도 많이 차지할 수 있다는 단점이 있습니다.
지금까지, 파일과 파일 시스템에 대해서 살펴보았습니다. 마무리로 실제 File System 사례를 살펴보겠습니다.
UNIX File System Management


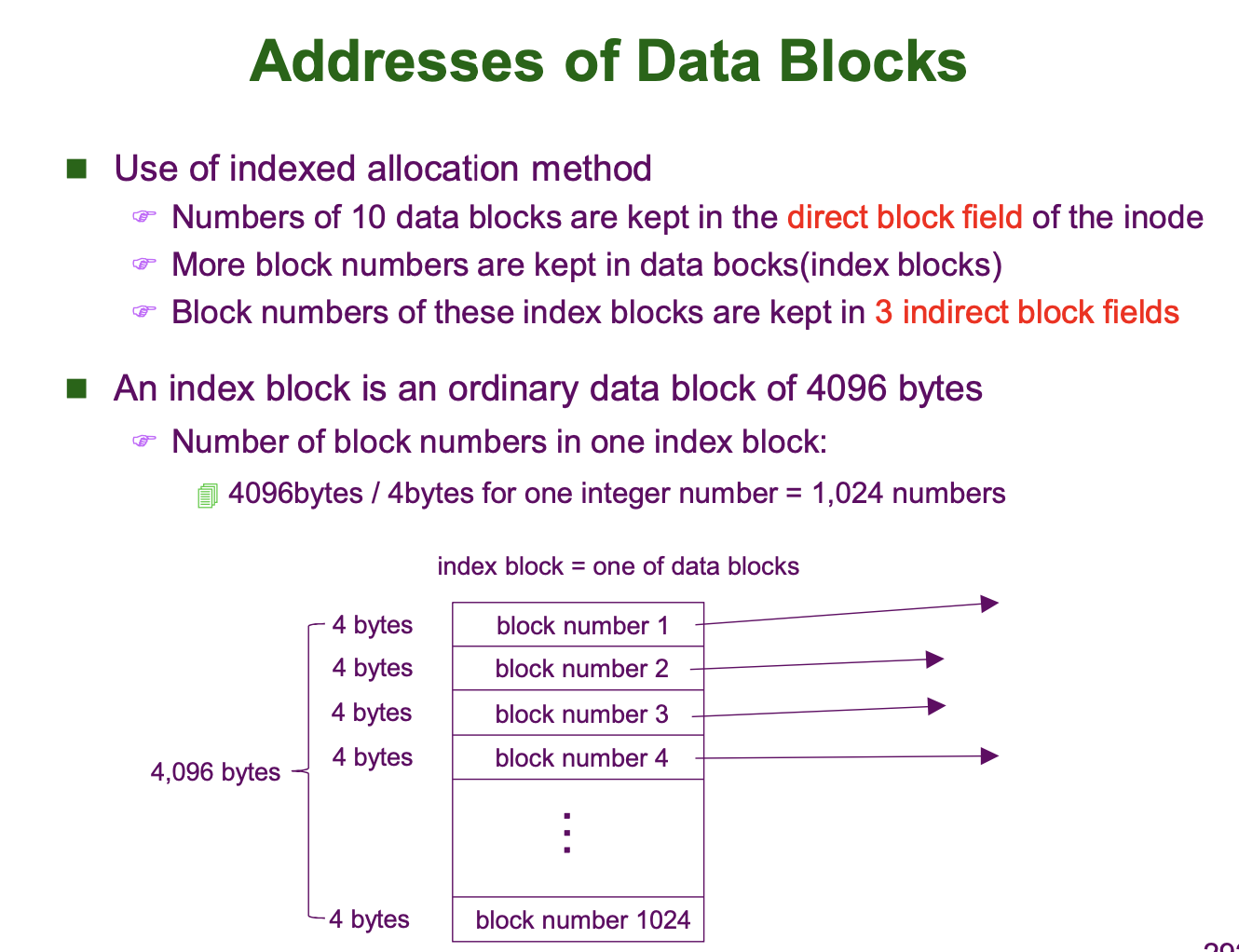
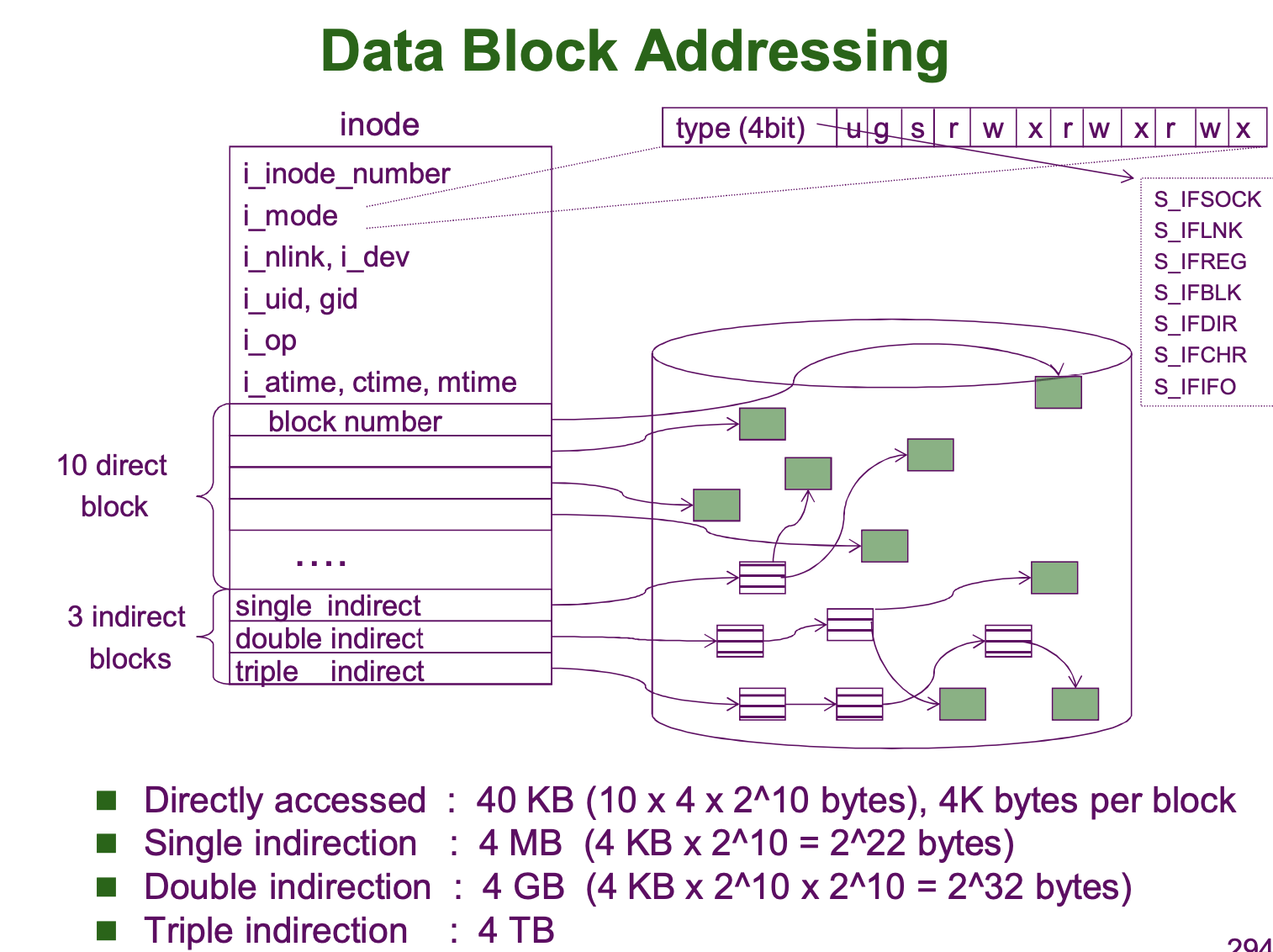
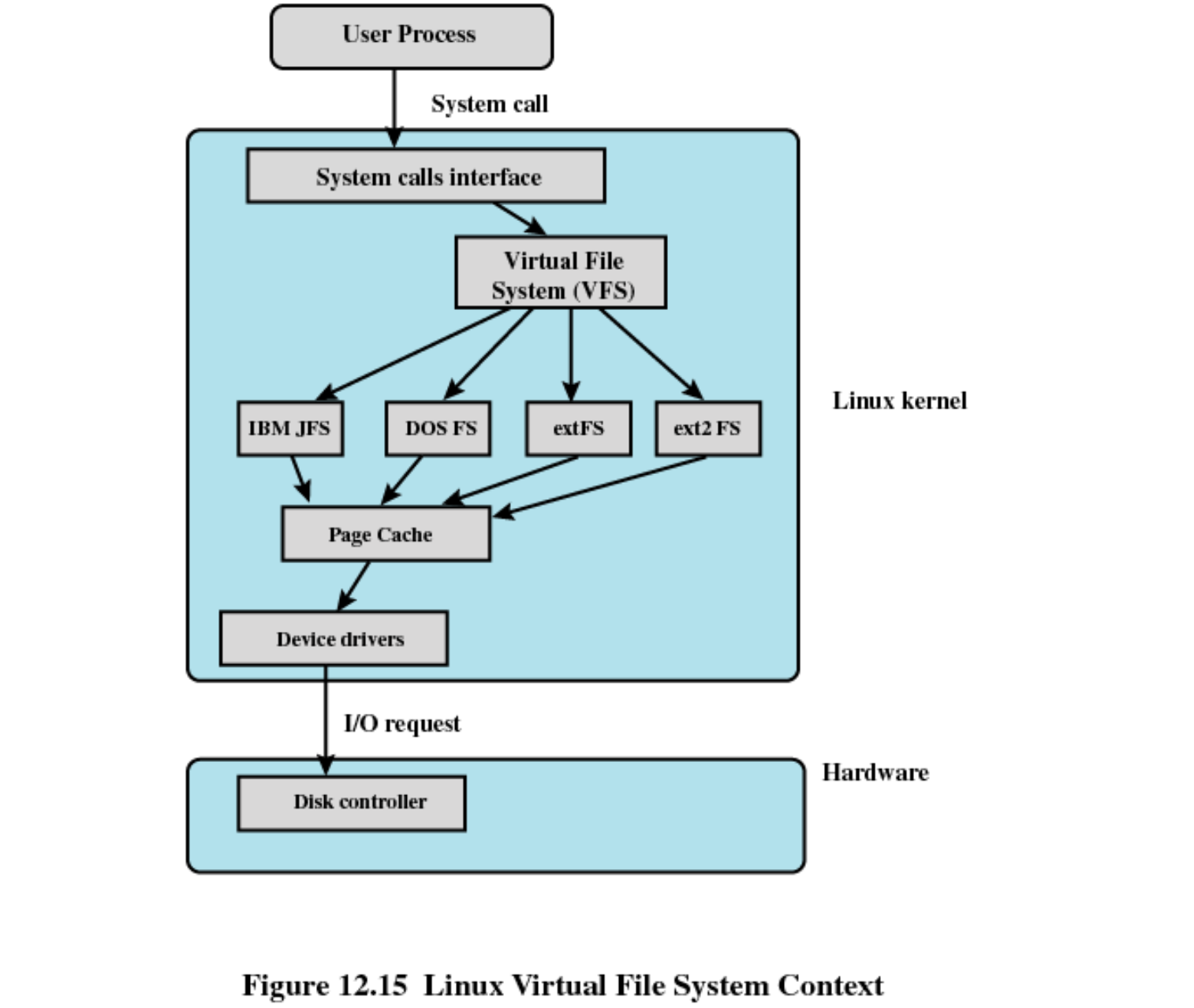
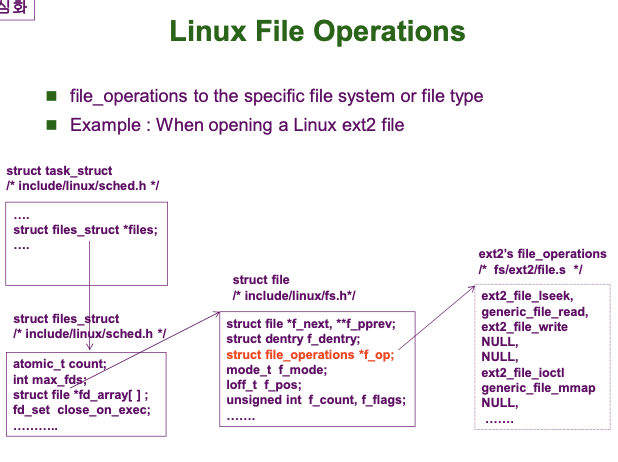
Linux File System Management

리눅스는 Virtual File System 을 가지고 있어 다양한 File system 에 대해서 File Operation 을 수행할 수 있습니다.