-
[Malloc Lab] Introduction to Malloc Lab시스템 프로그래밍 2022. 12. 4. 23:11
이번 포스팅에서는 malloc lab의 기본 구성에 대해 알아보겠습니다.
먼저 malloc lab 의 가정은 다음과 같습니다.
1. 메모리는 워드 단위로 주소가 지정됩니다. (Malloc Lab 에서 1Word 는 4Bytes입니다.)

free word 는 가용 메모리 공간을 의미합니다. 2. 응용 프로그램에서 무순의 할당과 반환 요청이 발생합니다. 반환 요청은 할당된 블록과 항상 pairing 이 되어야 합니다.
3. Allocator 는 이미 할당된 블록의 개수와 크기는 조정할 수 없습니다.
4. Allocator는 모든 할당 요청에 즉시 반응해야 합니다. 즉, 요청 순서를 변경하거나, 요청을 buffer 에 저장해 둘 수 없습니다.
5. Allocator 는 메모리 블록을 반드시 free Memory 에서 할당해야 합니다.
6. 블록들은 모든 주소 맞춤 요건을 만족하도록 정렬되어야합니다. 리눅스 컴퓨터의 GNU malloc 에서는 8bytes 정렬(Double Words)을 사용합니다.
7. Allocator는 프리메모리만을 관리하고 수정할 수 있습니다.
8. 일단 할당된 블록들은 이동할 수 없습니다. 즉, 블록 압축은 사용할 수 없습니다.
어떻게 malloc / free 를 짜야 우수한 malloc / free 일까요?
Main Goal :
- malloc과 free 수행 시 우수한 시간 성능을 얻는 것, 이상적으로는 상수시간만이 소요되는 것입니다. (언제나 가능한 것은 아닙니다.) 당연히 블록 수에 비례하는 시간이 소요되면 안됩니다.
- 우수한 공간 이용률을 가져야합니다. 유저가 할당한 구조체는 힙의 많은 부분을 차지해야합니다. 힙을 확보해 놓고(brk) 적은 공간만을 사용하면 비효율적인 malloc 이겠지요? 그리고 단편화(fragmentation) 을 최소화 해야합니다.
Sub Goal :
- 우수한 지역성을 가져야합니다. 시간적으로 인접해서 할당된 구조체는 공간상으로 인접해야합니다.
- 유사한 객체들은 인접공간에 할당되어야 합니다. 자주 쓸 일이 많은 것끼리 모아놓아야, CPU가 cache에 데이터를 저장할 때 다시 memory를 참조하여 cache에 데이터를 불러오는 일이 적어집니다.
- 견고성을 가져야합니다. free(p1) 이 유효한 포인터 p1에 대해 수행하는 지 판단할 수 있어야합니다.
- 메모리 참조가 할당된 공간에 대해 수행되는 지 판단할 수 있어야합니다. 가용 공간에 free를 하면 안됩니다.
위의 Goal들을 바탕으로, 우수한 malloc / free를 평가할 수 있는 평가지표에 대해 알아보도록 하겠습니다.
1.Throughput
malloc과 free 요청이 (R1, R2, R3, ... , Rn-1) 같이 주어진다고 해봅시다. ( R : Request)
그러면 Throughput은 단위 시간동안 완료한 요청의 수로 정의할 수 있습니다. ex) 5000malloc + 5000free / 10sec = 1000opeartions / sec.malloc 과 free 에 소요되는 평균 처리시간을 최소화하면 throughput을 극대화 할 수 있습니다. 좋은 malloc 과 free의 목표는 처리량과 순간 메모리 사용량을 극대화 하는 것입니다. 이것은 종종 충돌합니다.
2. 최대 메모리 이용률
가상 메모리의 크기도 제한되어 있다는 것을 알고 작업해야합니다. 효율적인 heap 사용 지표는 peak heap utilization 을 씁니다. malloc 과 free 요청이 R0, R1, ... , Rn-1 과 같이 주어졌다고 가정해봅시다.
총 데이터 Pk 는 요청 Rk 가 처리된 후에, 전체 데이터 Pk 는 현재 할당된 데이터들의 합입니다. (malloc(p)는 p바이트의 데이터를 포함하는 메모리 블록을 리턴합니다.)
현재 힙의 크기는 Hk로 정의합니다. 이 때, Hk는 단조 증가한다고 가정합니다.
그렇다면 최대 메모리 이용율 Uk는 다음과 같이 정의할 수 있습니다.
Uk = (maxi<=k Pi) / Hk 즉, 확보한 전체 힙 크기 중 얼만큼을 사용했느냐가 최대 메모리 이용율이 됩니다.
Un-1을 가능한 모든 작업 순서에 대해서 극대화 한 malloc 이 좋은 malloc 입니다.
다음으로 동적 메모리 관리 시에 발생할 수 있는 단편화 문제에 대해 알아보겠습니다.
단편화는 내부 메모리 단편화(Internal Fragmentation)과 외부 메모리 단편화(External Fragmentation)으로 나눌 수 있습니다.
내부 메모리 단편화(Internal Fragementation)
내부 단편화는 일부 블록에서 블록 크기와 데이터 크기간의 차이로 인해 발생합니다. 이전 요청 패턴에 의해서만 영향을 받으므로 측정이 용이합니다.

블록 크기와 payload 간의 간극으로 인한 내부 단편화 외부 메모리 단편화(External Fragementation)
힙 전체 메모리를 합쳐보면 수용이 가능하지만 가용(free) 블록 하나의 크기가 작은 경우에 발생합니다. 외부 메모리 단편화 문제는 미래의 요청 패턴에 의해 결정되므로, 측정하기 어렵습니다.

남은 메모리 공간이 6보다 큼에도 외부 메모리 단편화 문제로 인해 malloc(6)을 수행할 수 없음 지금까지 malloc, free 의 목표와 발생할 수 있는 문제점에 대해 다뤄보았습니다. 이 다음으로는 malloc, free 구현 시 고려할 점에 대해 살펴보도록 하겠습니다.
구현 시 고려할 점
- 포인터 한 개로부터 얼마만큼의 메모리를 반환해야 하는지를 어떻게 알 수 있을까요? (free의 parameter는 주소 하나만 달랑 들어갑니다.)
- 가용 블록을 어떻게 관리해야할까요? (가용 블럭은 연속적으로 존재하지 않고, fragment 로 존재합니다.)
- 가용 블록보다 작은 크기의 구조체를 할당할 때, 남는 공간은 어떻게 해야할까요?
- 할당가능한 블록이 여러 개 존재할 때, 할당을 위한 블록은 어떻게 선택해야할까요?
- 반환된 블록을 다시 가용 블록으로 표시해야 하는데 어떻게 해야할까요?
먼저, Free를 통해 얼마만큼의 메모리를 반환해야 하는지 알아봅시다
일반적으로는, 블록 앞에 블록의 크기를 저장합니다. 블록의 크기를 저장한 이 워드를 헤더(Header)라고합니다.
매 할당 블록마다 추가적으로 1워드가 소요됩니다. 그리고 free 시에 이 header 도 같이 free 해주어야합니다.
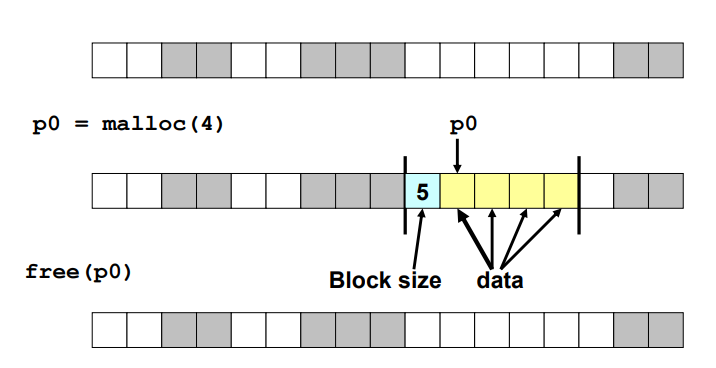
Header 를 이용한 블럭 크기 명시 다음으로, 가용 블럭 (Free Block) 을 어떻게 관리할 지 알아봅시다.
방법 1: 간접리스트 방식으로, 크기 정보를 이용하여 모든 블록을 연결합니다.
방법 2: 직접리스트 방식으로, 가용 블록 내에 포인터를 이용합니다.
방법 3: 구분 가용 리스트 (Segregated Free List) 방식으로, 크기 클래스마다 각각 별도의 가용 리스트를 유지합니다.
방법 4: 크기로 정렬된 블록을 이용합니다. 가용 블록 내에 포인터를 이용하고, 크기를 Key로 사용하여 균형 트리를 사용할 수 있습니다.
간접 리스트 방식부터 "구현 시 고려할 점" 을 하나씩 살펴보겠습니다.
먼저 각 블록이 비어있는 상태인지, 할당 상태인지 구분할 필요가 있습니다. 블록 크기를 2의 배수로 맞출 수 있다면, 헤더에 함께 이용하여 표현할 수 있습니다. 헤더에는 블록의 사이즈가 저장되었던 것을 기억하실텐데 블록 크기가 항상 짝수라면, 사이즈를 저장하는 bit 의 끝자리를 allocate 여부를 판단하는 bit로 사용해도 무방하겠습니다.
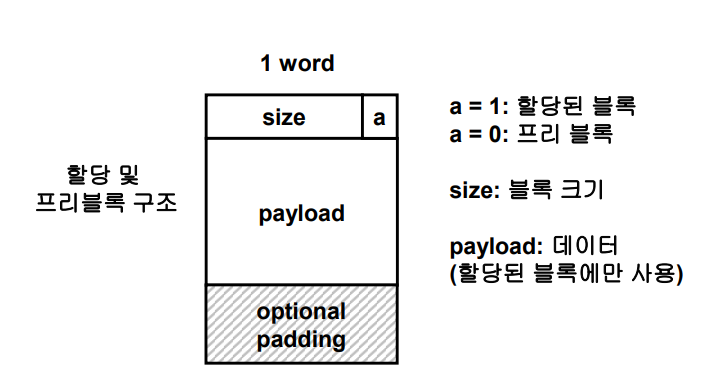
메모리 주소는 워드 단위로 지정했다는 가정을 기억하도록 합시다. Free 블록 (가용 블록) 은 어떻게 찾을 수 있을까요?
- 최초할당 (First Fit) : 힙 주소의 처음부터 검색을 시작해서 맨 처음 등장하는 크기가 맞는(fit한, assign 가능한) 블록을 할당합니다. 모든 블록(할당 및 가용 블록 전체)의 수에 비례해서, 시간이 소요됩니다. 실제로는 리스트 시작 부분에 작은 조각들이 다수 발생할 수 있습니다. (즉, 탐색 시간이 길어질 수 있습니다.)
- 다음할당 (Next Fit) : first-fit 과 유사하지만, 이전 검색이 종료된 위치에서 검색을 시작합니다. 단편화 성능은 first-fit 보다 안좋은 것으로 밝혀졌습니다.
- 최적할당 (Best Fit) : 리스트를 검색해서가장 근접한 크기의 블록을 선택합니다. 따라서 선택되는 블록의 조각을 작게해주어, 대부분의 단편화를 개선해줍니다. 대개, 최조할당보다 느리게 작동합니다.
가용 블록보다 작은 크기를 할당할 때 어떻게 처리해주어야 할 지 살펴보도록 합시다.
가용 블록보다 작은 크기를 할당할 때에는 가용 블록 (Free Block) 을 쪼갭니다.

void addblock 코드를 자세히 살펴봅시다. void addblock(ptr p, int len) 을 살펴봅시다. newsize 에 len+1을 2의 제곱 단위로 반올림합니다. 그리고 oldsize 에 가용블록의 Header 부분에 저장된 정보 (Blocksize, Allocated) 와 -2를 & 연산을 통해 masking 함으로써, blocksize 를 저장할 수 있습니다. 새로, *p의 헤더에 newsize, Allocated 정보를 저장해주고, 만약 newsize 가 oldsize보다 작다면, newsize 이후 남는 블록은 oldsize - newsize 의 blocksize를 갖는 가용 블록 (free) 으로 표시해줄 수 있도록 *(p+newsize) = oldsize - newsize 를 수행합니다.
반환된 블록을 다시 가용블록으로 표시하려면 어떻게 해야할까요?
가장 간단한 방법으로는 반환된 포인터의 헤더에 저장된 Allocated 정보를 0으로 set 해주면 됩니다. 하지만, 이 경우 잘못된 단편화가 발생할 수 있습니다. 아래 그림을 보며 이해해봅시다.

free block size는 6이 되어야하는데, 4와 2로 단편화 됩니다. 단순하게 Allocated 정보를 0으로 set 해주는 경우 (void free_block(ptr p) { *p = *p & -2 }) free(p) 이후, 가용 블럭의 크기는 6이 되어야 하지만, 4와 2로 단편화 됩니다. 즉, 가용 공간이 있음에도 불구하고, Memory Allocator 는 할당할 블록을 찾지 못합니다.
위 문제를 해결하는 방법으로 결합(Coalescing)을 제시합니다. 다음(next blcok) 또는 이전(previous block) 블록이 free 하면 함께 연결해서 더 큰 free 블럭을 만드는 것이 Coalescing 입니다.
next block 과 coalescing 하도록 보다 정교하게 설계된 void free_block 함수를 살펴보겠습니다.

다음 블럭 (Next Block)과 Coalescing 할 수 있게 설계된 free_block next 변수에 다음 block pointer 의 주소를 간접 리스트 방식으로 참조하여 coalescing 가능 여부를 확인한 후 coalescing 합니다. 다음 블럭을 coalescing 하는 법은 알겠는데 이전 블럭 (previous block)과 coalescing 해야하는 경우는 어떻게 해야할까요?
바로, 경계 태그 (Boundary Tags) 를 이용하는 것입니다. 가용블록의 마지막에 헤더와 같은 내용을 복사하여 저장합니다. 이를 통해 리스트를 거꾸로 따라갈 수 있게 해줍니다. 그러나, 추가적인 공간이 소요된다는 점에서 내부 단편화가 발생할 수 있습니다.

Boundary Tag Boundary Tag를 이용하여 상수 시간으로 coalescing 하는 방법을 살펴보겠습니다.

free 후 coalescing 가능한 Case 4가지 Case 1 의 경우 coalescing

Case 2 의 경우 coalescing

Case 3 의 경우 coalescing
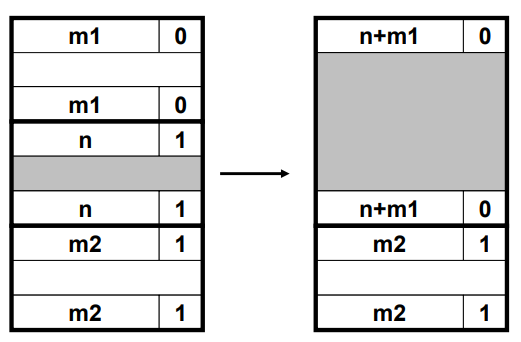
Case 4 의 경우 coalescing

지금까지 간접 리스트 방식으로, malloc 과 free 를 구현하는 방법에 대해 알아보았습니다.
요약하면 간접 리스트 방식은 malloc 시 worst case 에 linear time complexity 가 소요되고, free 시에는 constant time 에 수행할 수 있었습니다. 메모리 utilization 은 어떤 fit 방식을 사용하느냐에 따라서 달랐습니다.
다음으로는 직접 리스트방식으로 malloc 과 free 를 구현하는 방법에 대해 알아보도록 하겠습니다.
직접 리스트 방식은 다음과 같이 포인터가 지정되어 있습니다.

다음 가용 블럭 (Free block) 의 위치는 정해지지 않습니다. 위와 같이 다음 가용 블럭의 위치가 정해지지 않으므로, 포인터를 통해 다음 가용 블럭의 위치를 저장해야합니다.
공간 상으로 인접해있는 블록들을 연결하기 위해서 경계 태그 (Boundary Tag, Footer) 를 이용합니다.
직접 리스트 방식을 이용하는 경우에, 가용블럭들만 관리하면 되므로, 추가적인 워드의 소모없이 가용블럭의 payload 영역을 이용하여, preceed block 과 succeed block을 저장할 수 있습니다. 다음 그림을 통해 이해해봅시다.

다시 한번, malloc lab 에서 메모리 주소의 지정은 워드단위로 지정되었다는 것을 떠올립시다. Linked List 처럼 구현되어 있으므로, Free Block (가용 블럭) 은 다음과 같이 구성되어 있게됩니다.

직접 리스트 방식에서 가용블럭의 구조 가용 블럭 내에 작은 사이즈를 malloc 할 때 쪼개기가 어떻게 이루어지는 지에 대한 설명입니다.

linked list 방식으로 쪼개기 구현 직접 리스트 방식에서 Free 작업을 수행할 경우 반환된 가용 블럭 (free block)은 가용 블록을 가지고 있는 linked list 상의 어디에 위치시켜야 할까요? LIFO를 사용하여 위치를 지정해 줄 수 있습니다.
LIFO 의 장점은 간단하고 constant time 에 수행할 수 있다는 것이며, 단점은 단편화가 주소 정렬 방식보다 나빠진다는 것입니다.
직접 리스트 방식에서 coalescing 을 어떻게 수행하는 지 알아봅시다.
free 후 coalescing 가능한 Case 4가지 직접 리스트의 LIFO 방식에서 Case 1.
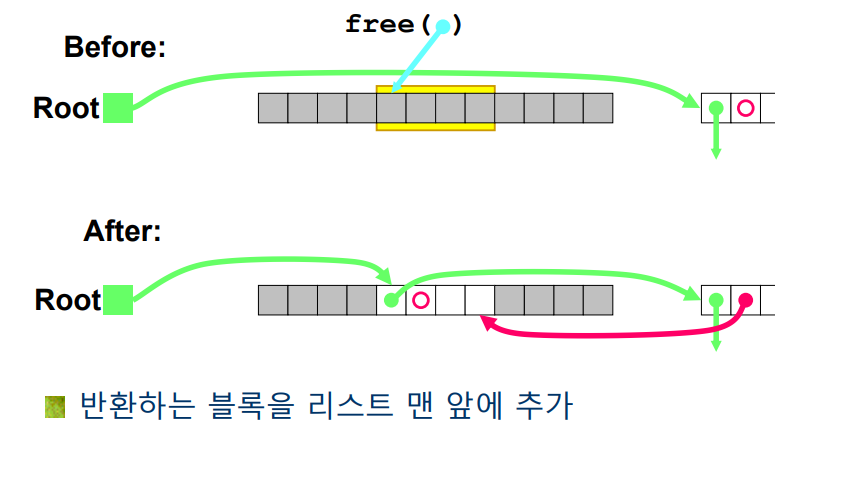
직접 리스트의 LIFO 방식에서 Case 2.

직접 리스트의 LIFO 방식에서 Case 3.

직접 리스트의 LIFO 방식에서 Case 4.

직접 리스트에 대해 요약해보겠습니다.
직접 리스트 (Explicit List) 방식은 할당 시간이 전체 블록의 수가 아니라 가용 블록 수에 비례합니다. 메모리가 거의 차 있는 경우에 매우 빠른 malloc 성능을 가집니다.
할당과 반환과정이 간접 리스트 (Implicit List) 에 비해 약간 더 복잡합니다. 그 이유는 블록들을 리스트에 추가했다가 떼어냈다가 하는 작업이 필요하기 때문입니다.
'시스템 프로그래밍' 카테고리의 다른 글
[Malloc Lab] Implicit List (0) 2022.12.04 [Malloc Lab] Naive List (0) 2022.12.04 [System Programming] 동적 메모리 할당 (Dynamic Memory Allocate) (0) 2022.11.26 [Shell lab] Trace 09, Trace 12 (0) 2022.11.24 [Shell lab] Trace 08, Trace 10, Trace 11 (0) 2022.11.23